
Nvidia's possible delay of Blackwell GPUs for AI and HPC applications will not have a dramatic impact on AI server makers and the AI server market, according to Supermicro, a major server supplier. The comment by Charles Liang (via SeekingAlpha), chief executive of Supermicro, can be considered confirmation that Nvidia's next-generation B100 and B200 processors are indeed delayed as they need rework.
"We heard Nvidia may have some delay, and we treat that as a normal possibility," Liang said during the company's earnings call with financial analysts and investors. He stated, "When they introduce a new technology, new product, [there is always a chance] there will be a push out a little bit. In this case, it pushed out a little bit. But to us, I believe we have no problem to provide the customer with a new solution like H200 liquid cooling. We have a lot of customers like that. So, although we hope better deploy in the schedule, that's good for a technology company, but this push out overall impact to us. It should be not too much."
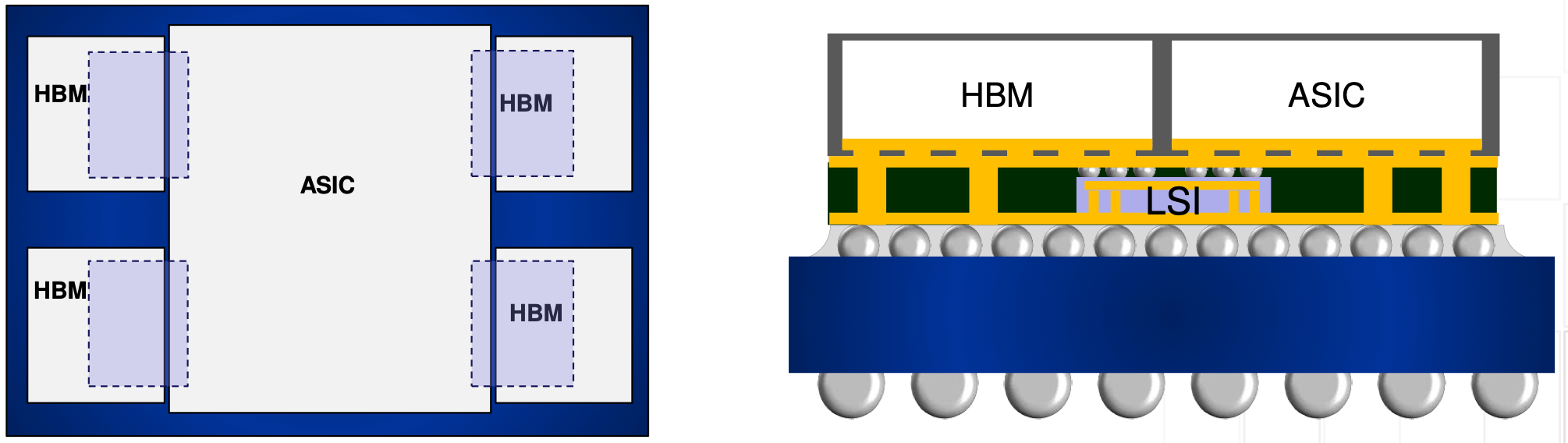
Nvidia's B100 and B200 GPUs are the industry's first products to use TSMC's CoWoS-L packaging with a Super Carrier interposer. It enables the building of system-in-packages up to six times the reticle size by using active or passive local silicon interconnect (LSI) bridges integrated into a redistribution layer (RDL) interposer (instead of a silicon interposer in the case of CoWoS-S used for H100).
The placement of the bridge dies demands exceptional precision, particularly for the bridges between the two main compute dies, as they are essential for maintaining the 10 TB/s chipset-to-chipset interconnect. A significant design issue is rumored to involve these bridge dies, necessitating their redesign. Analysts from SemiAnalysis imply that there could be a coefficient of thermal expansion (CTE) mismatch between the GPU chiplets, LSI bridges, the RDL interposer, and motherboard substrate, which causes warpage and failure of the whole SiP. It has never been officially confirmed, though. Additionally, there are reports of a required redesign of the top global routing metal layers and bumps out of the Blackwell GPU silicon, which means a multi-month delay.
SemiAnalysis reports that Nvidia will still produce 1000W B200 in low volumes in Q4 2024 for HGX servers, as planned, partly due to limited CoWoS-L capacity and partly due to the aforementioned issues. Also, high-end GB200-based NVL36 and NVL72 servers (using 1200W B200) will be available to some customers, albeit in low volumes in the fourth quarter.
To fulfill the demand for lower-end and mid-range AI systems, Nvidia is working on its B200A product featuring a monolithic B102 silicon with 144 GB (four stacks) of HBM3E and packaged using good-old CoWoS-S (or competing technologies from Amkor, ASE, SPIL, or even Samsung). This part is due in the second quarter of 2025. The new model will be available in 700W and 1000W HGX form factors, featuring up to 144GB of HBM3E memory and up to 4 TB/s of memory bandwidth. However, it is essential to note that this offers less memory bandwidth than the H200. However, whether the B102 die has anything to do with the graphics-oriented GB202 processor for graphics cards is unclear.
We do not know whether Nvidia plans to redesign the original B200, its LSI, or the package itself. Still, SemiAnalysis claims that Nvidia is working on the mid-generation upgrade of the Blackwell series called the Blackwell Ultra. The 'Ultra' lineup will use two chiplets, CoWoS-L packaging, formally called B210 or B200 Ultra. The Blackwell Ultra includes a memory upgrade to up to 288 GB of 12Hi HBM3E and a performance boost in FLOPS of up to 50%.
Nvidia's B210/B200 Ultra is expected to be available in 1000W and 1200W versions sometime in Q3 2025, so the delay of high-end, high-volume Blackwell GPUs seems significant. Considering the demand for AI servers in general and Nvidia's H100/H200 GPUs, the green company will likely manage to navigate its B200-related issues.







