
Intel held its Data Center and AI Investor Webinar today, revealing that Sierra Forest, its first-gen efficiency Xeon, will come with an incredible 144 cores, thus offering better core density than AMD’s competing 128-core EPYC Bergamo chips. The company even teased the chip in a demo at its event. Intel also revealed the first details of Clearwater Forest, it's second-gen efficiency Xeon that will debut in 2025. Intel skipped over its 20A process node for the more performant 18A for this new chip, which speaks volumes about its faith in the health of its future node. The company also presented new products and performance demos alongside a roadmap update that shows the company’s Xeon is moving along on schedule.
Intel also presented several demos, including head-to-head AI benchmarks against AMD’s EPYC Genoa that show a 4X performance advantage for Xeon in a head-to-head of two 48-core chips, and a memory throughput benchmark that showed the next-gen Granite Rapids Xeon delivering an incredible 1.5 TB/s of bandwidth in a dual-socket server.
Intel’s disclosures, which include many other developments that we’ll cover below, come as the company executes on its audacious goal of delivering five new nodes in four years, an unprecedented pace that will power its broad data center and AI portfolio that includes CPUs, GPUs, FPGAs, and Gaudi AI accelerators.
Intel has lost the performance lead in the data center to AMD, and its path to redemption has been marred by delays to its Sapphire Rapids and GPU lineups. However, the company says it has solved the underlying issues in its process node tech and revamped its chip design methodology to prevent further delays to its next-gen products. Let’s see what the roadmap looks like.
Intel Xeon CPU Data Center Roadmap

Intel's roadmap for its existing Xeon products remains intact and on schedule since the last update in February 2022, but it now has a new entrant — Clearwater Forest. We'll cover that chip in detail further below.
Intel's data center roadmap is split into two swim lanes. The P-Core (Performance Core) models are the traditional Xeon data center processor with only cores that deliver the full performance of Intel's fastest architectures. These chips are designed for top per-core and AI workload performance. They also come paired with accelerators, as we see with Sapphire Rapids.
The E-Core (Efficiency Core) lineup consists of chips with only smaller efficiency cores, much like we see present on Intel's consumer chips, that eschew some features, like AMX and AVX-512, to offer increased density. These chips are designed for high energy efficiency, core density, and total throughput that is attractive to hyperscalers. Intel's Xeon processors will not have any models with both P-cores and E-cores on the same silicon, so these are distinct families with different use cases.
Here we can see how Intel’s roadmap looks next to AMD’s data center roadmap. The current high-performance battle rages on between AMD’s EPYC Genoa, launched last year, and Intel’s Sapphire Rapids, launched early this year. Intel has its Emerald Rapids refresh generation coming in Q4 of this year, which the company says will come with more cores and faster clock rates, along with its HBM-infused Xeon Max CPUs. AMD has its 5nm Genoa-X products slated for release later this year. Next year, Intel’s next-gen Granite Rapids will square off with AMD’s Turin.
In the efficiency swim lane, AMD’s Bergamo takes a very similar core-heavy approach as Sierra Forest by leveraging AMD’s dense Zen 4c cores, but it will arrive in the first half of this year, while Intel’s Sierra Forrest won’t arrive until the first half of 2024. AMD hasn’t said when its second-gen e-core model will arrive, but Intel now has its Clearwater Forest on the roadmap in 2025.
Intel E-Core Xeon CPUs: Sierra Forest and Clearwater Forest


Intel’s e-core roadmap begins with the 144-core Sierra Forest, which will provide 256 cores in a single dual-socket server. The fifth-generation Xeon Sierra Forest’s 144 cores also outweigh AMD’s 128-core EPYC Bergamo in terms of core counts but likely doesn’t take the lead in thread count — Intel’s e-cores for the consumer market are single-threaded, but the company hasn’t divulged whether the e-cores for the data center will support hyperthreading. In contrast, AMD has shared that the 128-core Bergamo is hyperthreaded, thus providing a total of 256 threads per socket.
We also don’t know the particulars of performance for Intel or AMD’s dense cores, so we won’t know how these chips compare until silicon hits the market. However, we do know that Intel’s e-cores don’t support some of the ISA it supports with its p-core; Intel omits AVX-512 and AMX to ensure the utmost density, while AMD’s Bergamo Zen 4c cores support the same features as its standard cores.
Intel’s Sierra Forest is apparently well on track for the first half of 2024, though: Images of the Mountain Stream systems have already leaked online, including pictures of the massive LGA7529 socket you can see below. This socket will house both the e-core Sierra Forest and p-core Granite Rapids processors (more on Granite below).

This indicates that the Sierra Forest platforms are already with Intel’s partners, and the company also tells us that it has powered on the silicon and had an OS booting in less than 18 hours (a company record). This chip is the lead vehicle for the ‘Intel 3’ process node, so success is paramount. Intel is confident enough that it has already sampled the chips to its customers and demoed all 144 cores in action at the event. Intel initially aims the e-core Xeon models at specific types of cloud-optimized workloads but expects them to be adopted for a broader range of use cases once they are in the market.
Intel also announced Clearwater Forest for the first time. Intel didn’t share many details beyond the release in the 2025 timeframe but did say it will use the 18A process for the chip, not the 20A process node that arrives half a year earlier. This will be the first Xeon chip with the 18A process. Intel tells us that the compressed nature of its process roadmap — the company plans to deliver five nodes in four years — gave it the option to choose either the 18A process that arrives in 2024 or the 20A process that is production ready in the second half of 2024.
The 18A node is Intel’s second-gen ‘Angstrom’ node and is analogous to 1.8nm. Intel’s first-gen Angstrom node, 20A, will incorporate RibbonFET, a gate-all-around (GAA) stacked nanosheet transistor tech, and Intel’s PowerVia backside power delivery (BSP) technology. The 18A process that Intel will use for Clearwater Forest will have a 10% improvement in performance-per-watt over 20A, along with other improvements, so Intel chose to go with this node as it is the best the company has to offer in the timeframe of the Clearwater launch.
The 18A process features all the leading-edge tech the industry intends to adopt in the future, like GAA and BSP, so it represents an incredibly advanced node. Intel claims that the 18A node is where it will gain clear process leadership over its rivals TSMC and AMD, and the company’s decision to skip 20A and move to 18A for Xeon certainly speaks volumes to its confidence in the health of the node. Intel also tells us we won’t see a Xeon model fabbed on 20A.
Intel P-Core Xeon CPUs: Emerald Rapids and Granite Rapids
Intel’s next-gen Emerald Rapids is scheduled for release in Q4 of this year, a compressed timeframe given that Sapphire Rapids launched a few months ago. Emerald will drop into the same platforms as Sapphire Rapids, reducing validation time for its customers, and is largely a refresh of Sapphire Rapids. However, Intel says it will provide faster performance, better power efficiency, and, more importantly, more cores than its predecessor. Intel says it has the Emerald Rapids silicon in-house and that validation is progressing as expected, with the silicon either meeting or exceeding its performance and power targets.
Granite Rapids will arrive in 2024, closely following Sierra Forest. Intel will fab this chip on the ‘Intel 3’ process, a vastly improved version of the ‘Intel 4’ process that lacked the high-density libraries needed for Xeon. This is the first p-core Xeon on ‘intel 3,’ and it will feature more cores than Emerald Rapids, higher memory bandwidth from DDR5-8800 memory, and other unspecified I/O innovations.
Notably, Sierra Forest, the first E-core-equipped family, will be socket compatible with the P-core-powered Granite Rapids; they even share the same BIOS and software. Intel enabled this by moving these chips to a tile-based design, with a central I/O tile handling memory and other connectivity features, much like we see with AMD's EPYC processors. This separates the core and uncore functions, so Intel creates different processor types by using different types of compute tiles. This provides multiple benefits, such as the ability to use the same systems to pack in more threaded heft with E-cores, but within the same TDP envelope as P-core models.
During its webinar, Intel demoed a dual-socket Granite Rapids providing a beastly 1.5 TB/s of DDR5 memory bandwidth; a claimed 80% peak bandwidth improvement over existing server memory. For perspective, Granite Rapids provides more throughput than Nvidia’s 960 GB/s Grace CPU superchip designed specifically for memory bandwidth, and more than AMD’s dual-socket Genoa, which has a theoretical peak of 920 GB/s. Intel accomplished this feat using DDR5-8800 Multiplexer Combined Rank (MCR) DRAM, a new type of bandwidth-optimized memory it invented. Intel has already introduced this memory with SK hynix.
Granite Rapids and Sierra Forest are the intercept point for Intel’s recent restructuring of its chip design flow process, which should help avoid the issues that found the company doing multiple successive steppings of the Sapphire Rapids processors that led to further delays. Intel says Granite Rapids is much further along in its development cycle than Sapphire Rapids was at this point. Intel says that Granite Rapids is hitting all engineering milestones, and the first stepping is healthy. As such, it is already sampling to customers now.
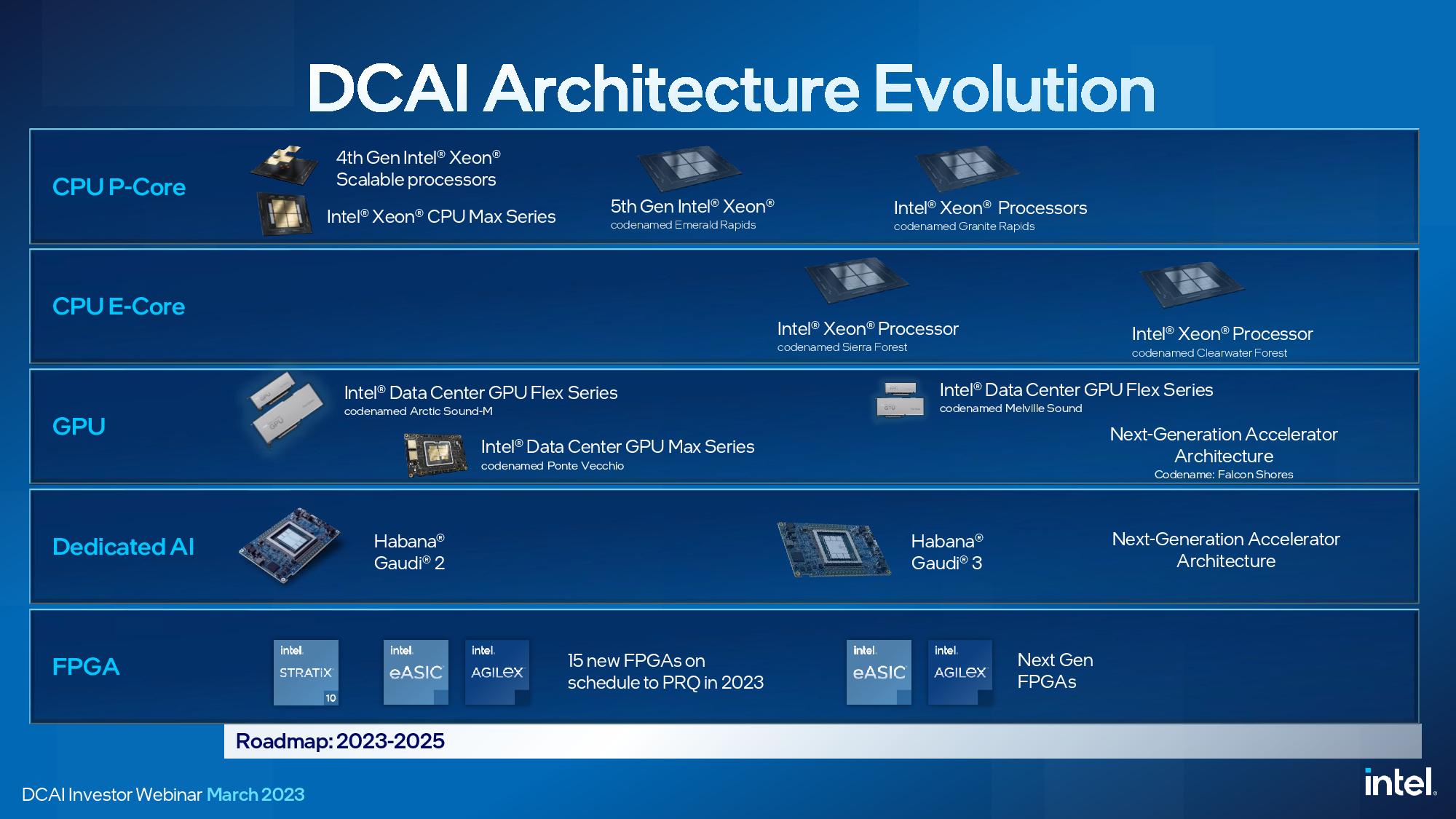

Intel’s data center and AI update focused on Xeon, but the company’s portfolio also includes other additives, like FPGAs, GPUs, and purpose-built accelerators. Intel has many competitors in the custom silicon realm, like Google with its TPU and Argos video encoding chip (among many other companies), so the Gaudi accelerators and FPGAs are an important part of its portfolio. Intel said it would launch 15 new FPGAs this year, a record for its FPGA group. We have yet to hear of any major wins with the Gaudi chips, but Intel does continue to develop its lineup and has a next-gen accelerator on the roadmap. The Gaudi 2 AI accelerator is shipping, and Gaudi 3 has been taped in.
Intel also says that its Artic Sound and Ponte Vecchio GPUs are shipping, but we aren’t aware of any of the latter available on the general market — instead, the first Ponte Vecchio models appear to be headed to the oft-delayed Aurora supercomputer.
Intel recently updated its GPU roadmap, canceling its upcoming Rialto Bridge series of data center Max GPUs and moving to a two-year cadence for data center GPU releases. The company's next data center GPU offerings will come in the form of the Falcon Shores chiplet-based hybrid chips, but those won’t arrive until 2025. The company also pared back its expectations for Falcon Shores, saying they will now arrive as a GPU-only architecture and won’t include the option for CPU cores as originally intended — those “XPU” models now don’t have a projected release date.
Intel predicts that AI workloads will continue to be run predominantly on CPUs, with 60% of all models, mainly the small- to medium-sized models, running on CPUs. Meanwhile, the large models will comprise roughly 40% of the workloads and run on GPUs and other custom accelerators.
Intel is also working to build out a software ecosystem for AI that rivals Nvidia’s CUDA. This also includes taking an end-to-end approach that includes silicon, software, security, confidentiality, and trust mechanisms at every point in the stack. You can learn more about that here.
Thoughts.
Intel's pivot to AI-centric designs for its CPUs began several years ago, and today's explosion of AI into the public eye with large language models (LLMs) like ChatGPT proves this was a solid bet. However, today's AI landscape is changing daily. It spans an entire constellation of lesser-known and smaller models, making it a fool's errand to optimize new silicon for any one algorithm. That's especially challenging when chip design cycles span up to four years — many of today's AI models didn't exist back then.
We spoke with Intel Senior Fellow Ronak Singhal, who explained that Intel chose long ago to focus on supporting the fundamental workload requirements of AI, like compute power, memory bandwidth, and memory capacity, thus laying a broadly-applicable foundation that can support any number of algorithms. Intel has also steadily expanded its support for different data types, like AVX-512 and its first-gen AMX matrix multiplication tech that is shipping now with support for 8-bit integer and bfloat16. Intel hasn't told us when its second-gen AMX will arrive, but it will support FP16 and has the extensibility to support more data types in the future. This foundation of support has enabled Intel to provide impressive performance with Xeon in many different types of AI workloads, often exceeding AMD's EPYC.
Yes, many AI models are far too large to run on CPUs, and most training workloads will remain in the domain of GPUs and custom silicon, but smaller models can run on CPUs — like Facebook's LlaMa, which can even run on a Raspberry Pi — and more of today's inference workloads run on CPUs than any other type of compute — GPUs included. We expect that trend will continue with the smaller inference models, and Intel is well positioned for those workloads with its P-core Xeon roadmap.
Intel has no shortage of competitors, and the Arm ecosystem is becoming far more prevalent in the data center, with Amazon's Graviton 2, Tencent's Yitian, Ampere Altra in Microsoft Azure, Oracle Cloud, and Google Cloud, Nvidia with Grace CPUs, Fujitsu, Alibaba, Huawei with Kunpeng, and Google's Maple and Cypress, to name a few. There are even two exascale-class supercomputer deployments planned with Arm Neoverse V1 chips: SiPearl "Rhea" and the ETRI K-AB21.
This means that Intel, like AMD, needs to employ optimized chips that focus more on power efficiency and core density to assuage the hyperscalers and CSPs migrating to Arm. This comes in the form of the e-core Xeon models from Intel and the Bergamo chips from AMD. If AMD delivers on its roadmap, and there's no reason to believe it won't, it will beat Intel to market with its density-optimized Bergamo. That could put Intel at a disadvantage in the high-volume (but lower-margin) cloud market. On the other hand, Intel does plan to move to what *could* be a more advanced node for its follow-on Clearwater Forest models than AMD will have, making for interesting competition in 2025.
Given the company's recent history, the fact that Intel remains steadfast in the Xeon roadmap it shared last year is encouraging. The accelerated adoption of the 18A node also speaks volumes about the company's broader foundational process technology that impacts all facets of its businesses.







