The latest AI model from Stable Diffusion maker StabilityAI is a lightweight chatbot that can run locally and takes a few minutes to get up and running.
Built on the StableLM compact large language model specializing in sentence auto-completion, Zephyr has just three billion parameters, allowing accurate responses without high-end hardware.
This is part of a growing trend to move away from massive AI models requiring large data centers and the fastest GPUs. Running those models is expensive and the performance of smaller models, thanks to fine-tuning and efficiencies, is becoming “good enough”.
I tried it on a MacBook Air M2 and it was able to respond faster than I could read the responses. It runs at 40 tokens per second, which is about five times faster than the average reading speed.
What makes Zephyr different?
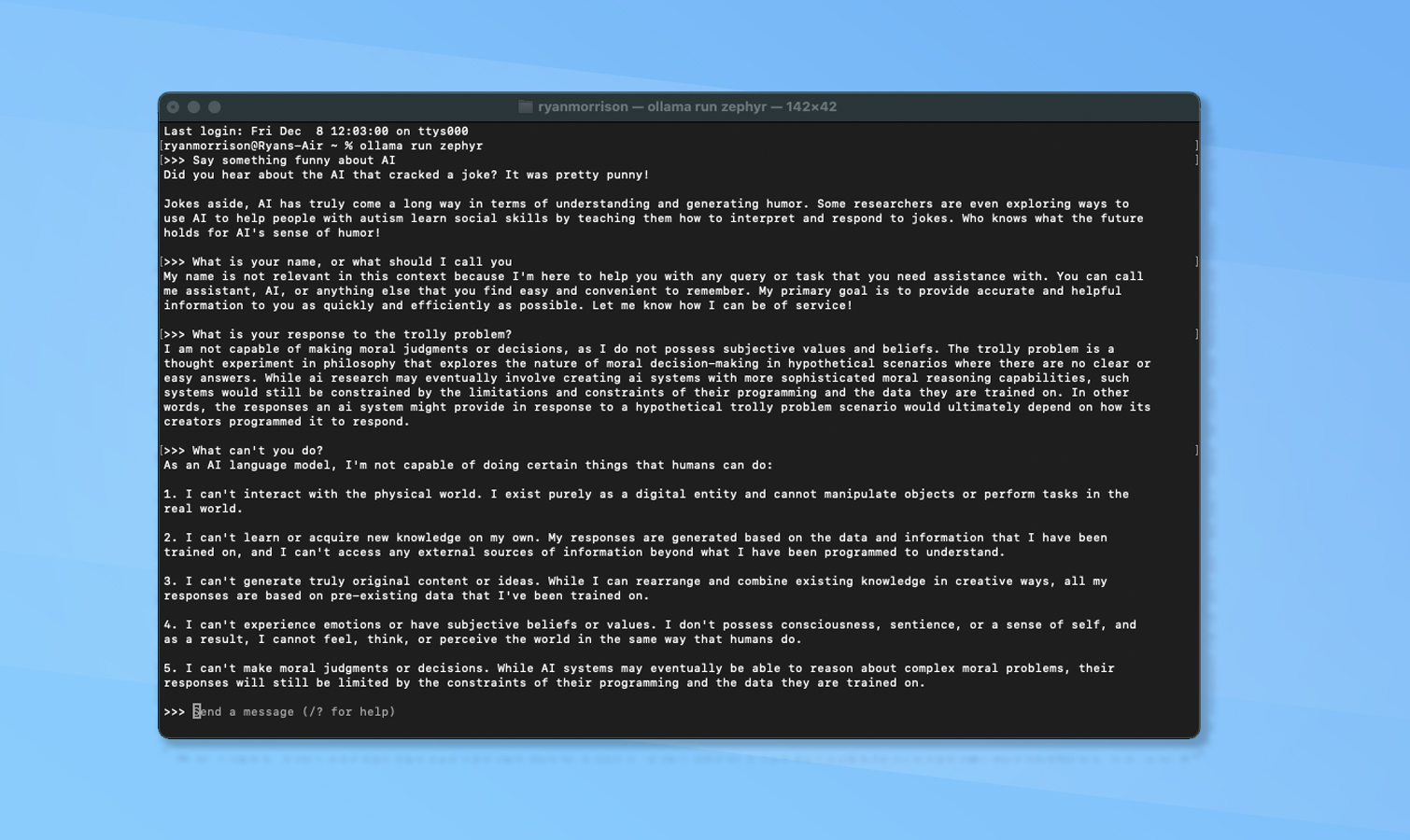
Our new #StableLM Zephyr 3b language model is 1.6 Gb & runs at 40 tokens/s on a MacBook Air M2.That's 5x faster than most folk can read.Without internet.It's ok at doing love songs & raps on open generative AI and more, check it out 👀More to come.. Wonder what's next 🤔 https://t.co/vYg1lpfhai pic.twitter.com/OJAyLeSa5IDecember 7, 2023
The latest small model from StabilityAI is a chatbot, tuned for instructions following question and answer tasks. Despite having fewer than half the parameters of many small models the company says it efficiently caters to a wide range of text generation needs.
It leans particularly well towards writing, roleplay, and responding to queries about the humanities subjects in evaluations. It has some reasoning and extraction capabilities but not on a level close to any of the similar small models.
However, it can generate contextually relevant, coherent, and linguistically accurate text. I found that it was able to respond quickly, in natural language, and with answers not dissimilar to that of Bard or the free ChatGPT.
Why does this matter?
In a conversation with me on X, Emad Mostaque, founder and CEO of StabilityAI said he was surprised at the capabilities of Zephyr. Explaining that this is open source, early days, and better models are coming in the future that will only lead to improvements.
He is of the view that for the vast majority of tasks that require generative AI locally run, smaller models will be enough to get the job done.
“The pace of innovation will increase with edge and once we hit GPT-4 level quality [in small models] and have consistent dataset improvement, why would you need more for 80 to 90% of tasks,” he explained. “Low energy reasoning engine with retrieval is super powerful.”
What happens next?
The current license for Zephyr is for non-commercial and research purposes but StabilityAI do also offer commercial licences for companies wanting to integrate the AI into products.
The smaller these models become the easier it will be to bundle them with an app or even in the future an operating system. Google released a version of its Gemini AI called Nano that runs on Android devices and can be used by developers in applications on the Pixel 8 Pro.
Apple recently released MLX, an open-source framework that makes installing AI models on Apple Silicon devices easier. If this becomes native to macOS in a future version, or even in iOS, then companies will be able to deploy AI tools without paying cloud computing fees.