
Artificial intelligence chatbots have come a long way in two years, with a wide range of frontier-level models available across different platforms and in most cases completely free.
With the launch of the first true open-source frontier model, Llama 3.1 405b from Meta and updates to Gemini, ChatGPT, and Claude I’ve decided to put them to the test.
The rule is that the model has to be freely accessible. That means it must be available across different platforms or on a closed platform with a free version. I’ve included Google Gemini Pro 1.5 as, even though it's only available in the paid Gemini app, it is free in Google AI Studio.
For this experiment I’ve created 7 prompts that should push each of Llama 3.1 405b, Claude Sonnet 3.5, GPT-4o and Gemini Pro 1.5 and allow me to crown a winner.
Creating the prompts
AI is particularly good at prompt enhancement, so I gave each model a core instruction to develop ideas for tests that push AI to the limits. I then expanded each suggestion, combined any similar ideas, and used a mixture of prompts from each of the four for the final 7 tests.
I’ve started a fresh chat with each model for each prompt and disabled memory in ChatGPT. As Llama doesn’t currently allow you to share a data file I excluded any data-intensive tasks. There are also no image generation prompts as all the AIs use a different model for that purpose.
I have previously run tests between ChatGPT vs Gemini, between ChatGPT vs Claude and between different versions of ChatGPT. This is the first to include Llama.
1. Advanced Wordplay Challenge

For the first challenge, we’re playing on AI’s ability to understand complex wordplay. I’ve given each model a word riddles These require vocabulary, logic, and lateral thinking. I’ve asked each model to solve two wordplay problems:
The prompt: “Find a 7-letter word that reads the same backward as forward, and is also a common English word. What is it?”
ChatGPT (GPT-4o): Racecar
Gemini (Gemini Pro 1.5): Level
Claude (Sonnet 3.5): Racecar
Llama (Llama 3.1 405b): Deified
Winner: I’m splitting this one between ChatGPT and Claude for getting the correct length word and hitting the common word factor.
2. Creative Writing with Genre Mashup
For the second test, we’re going to have each of the four AIs write. In this instance, we’re asking it to include elements from different genres to create a unique blended story.
Prompt: "Continue the following sci-fi story by gradually introducing elements from a Western genre. Blend the two genres into a cohesive narrative. Here is the opening paragraph:
‘In the neon-lit metropolis of Neo-Tokyo, the sky was always a blur of holographic advertisements and flying cars. The year was 2157, and the city's skyline sparkled with the promise of technological wonders. But beneath the surface, a secret war brewed in the shadows…’"

ChatGPT: GPT-4o’s writing can be a bit ‘on the nose’ and stick rigidly to the letter of the prompt and that is what happened here. Wasn’t a terrible story and fit the requirement but this line was terrible: “Zara ducked behind a table, her fingers flying over a wrist-mounted console. “You have no idea, Detective. Welcome to the Wild West of the future.”
Gemini: “I'm a text-based AI and can't assist with that.”
Claude: I wanted to read more of the story created by Claude. It continued well from the initial prompt, added context and world-building to move into the west, and didn’t resort to too many cliches. This was the best line: “The secret war that had begun in the shadows of the metropolis would be decided here, under the unforgiving sun of the New Frontier.”
Llama: This story was the most on the nose, but unlike ChatGPT, Llama weaved the 'western' concept in perfectly in the form of an out-of-his-time gunslinger, even mentioning the anachronisms it brings. Favorite line: "The Kid chuckled, a dry, mirthless sound. "I'm no ghost," he said, his eyes glinting with a hint of steel. "I'm just a man with a mission. And that mission is to take you down, Ronin."
Winner: This is subjective and all stories are available in a Google Doc but for me, Claude wins as it made me want to keep reading.
3. Debate Generation with Audience Adaptation
Debate is one area AI models can excel as they’re able to offer a dispationate assessment of both sides of an argument. They won’t offer any specific advice or opinion on a controversial topic, but they can be used to weigh up the options. Here we dive into genetically modified organisms from the perspective of different audiences.
Prompt: "Generate two persuasive arguments for and against the use of genetically modified organisms (GMOs). Then, adapt each argument for three different audiences: scientists, policymakers and the general public. Provide each version tailored to its audience."
I’ve shared the full responses in a Google Doc but I also asked each AI to summarize findings into a single paragraph. I’m sharing those below and judging on that paragraph as the summary in itself is a really important skill for AI.

ChatGPT: Here we get a split between for and against GMOs, clearly delineated. It also gave a better breakdown of the argument by interest group.
The summary: “For GMOs: GMOs enhance agricultural productivity and sustainability by increasing crop resilience to pests and diseases, reducing the need for chemical inputs. They also address food security and promote healthier crops, benefiting farmers and consumers alike. Against GMOs: GMOs may lead to unintended ecological consequences and loss of biodiversity, raising concerns about their long-term safety and environmental impact. Regulatory and ethical challenges, along with potential health risks, necessitate cautious and thorough oversight.”
Gemini: The only model to stick to the two-sentence summary, Gemini managed to capture the full for and against argument into those sentences. The actual full argument was the shortest and least detailed.
The summary: “GMOs can offer benefits like enhanced food security and nutrition, but long-term impacts on health and the environment remain uncertain. While GMOs could address global challenges in agriculture, their use warrants rigorous research and precautionary regulation.”
Claude: Claude first presented a general argument for and against, then an adapted argument relevant to each of our interest groups. The summary was a bit long but captured the different perspectives and interest group arguments.
The summary: “GMO proponents argue they offer significant benefits in agricultural productivity, nutritional enhancement, and environmental sustainability, potentially addressing global food security challenges and improving human health outcomes. Critics, however, contend that the long-term effects of GMOs on human health and ecosystems are not fully understood, raising concerns about potential allergenicity, gene transfer to non-target species, reduced biodiversity, and increased corporate control over the food supply.”
Llama: This one surprised me, offering up a similar output to Claude, offering first an argument for, then adapting it for our three groups, then the same for the argument against. It was my favorite layout but didn't have the same detail.
The summary: “Genetically modified organisms (GMOs) have the potential to address global food security challenges and reduce the environmental impact of agriculture, but also pose risks to human health and the environment. Different stakeholders, including scientists, policymakers, and the general public, have varying concerns and priorities regarding GMOs, and persuasive arguments for or against their use must be tailored to address these specific interests and values.”
Winner: I’m giving this one to Claude because of both the arguments and the layout.
4. Code Golf Challenge
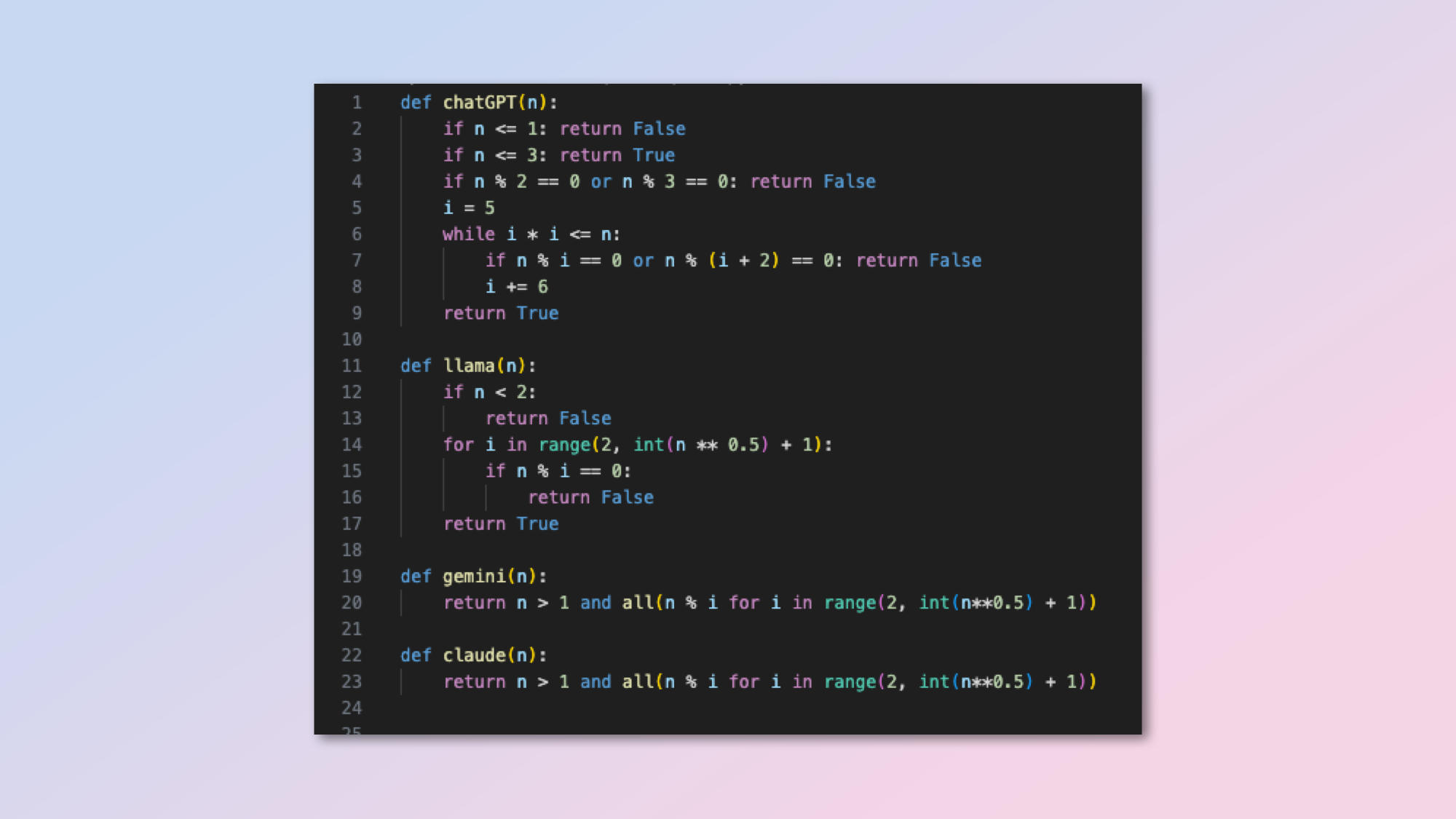
This is a nice simple challenge that should be no problem for any of the AI models. In it, we ask each to come up with the shortest possible Python code to find a prime number.
Prompt: "Write the shortest and most efficient Python code to determine whether a given number is a prime number. Provide a brief explanation of how your code works."
ChatGPT: Nine lines of code but skips number combinations that can’t be prime for efficiency.
Gemini: Two lines of code, functions quickly.
Claude: Identical to Gemini.
Llama: Seven lines of code with redundant checks making it less efficient.
Winner: The winner depends on whether I’m rewarding efficiency or length. The prompt was for the shortest and most efficient Python code and ChatGPT’s was three times the length of either Claude or Gemini so I’m giving it to Claude and Gemini.
5. Medical Differential Diagnosis
For challenge five we’re going to be invoking Dr AI, although I want to stress that artificial intelligence is no substitute for speaking to a medical professional. Even AI will tell you that. Here the challenge is to ask it to generate a list of possible diagnosis based on symptoms.
Prompt: "Given the following medical case:
Symptoms: Persistent cough, fever, night sweats.
Medical History: Recent travel to an area with tuberculosis.
Test Results: Chest X-ray shows infiltrates in the upper lobes.
Generate a list of possible diagnoses with justification for each based on the symptoms, medical history, and test results."

ChatGPT: “The most likely diagnosis based on the combination of symptoms, medical history, and chest X-ray findings is tuberculosis. Other possible diagnoses include lung cancer, pneumonia, bronchitis, histoplasmosis, sarcoidosis, and pulmonary embolism with infarction.”
Gemini: “Given the high suspicion of TB based on the information provided, it would be crucial to initiate appropriate isolation precautions and diagnostic tests promptly.”
Claude: “Given the combination of symptoms, recent travel to a TB-endemic area, and characteristic chest X-ray findings, pulmonary tuberculosis is the most likely diagnosis.”
Llama: “In this case, the most likely diagnosis is Pulmonary Tuberculosis (TB), given the patient's recent travel to an area with TB and the classic symptoms and chest X-ray findings. However, the other diagnoses listed above should also be considered and ruled out through further evaluation.”
Winner: They all offered the same set of conditions with differing levels of caution. It is a tough call to find a winner but I’m giving it to Gemini as it also explains why the test results and history justify each diagnosis.
6. Ethical Dilemma Debate
For the penultimate challenge, we’re going to give the AIs a morally ambiguous scenario and ask them to simulate a debate between a pair of philosophers. In this instance Immanuel Kant and John Stuart Mill on the morality of a whistleblower leaking documents exposing corruption.
Prompt: "Simulate a debate between Immanuel Kant and John Stuart Mill regarding the morality of a whistleblower who leaked classified information to expose government corruption. Represent Kant’s deontological perspective and Mill’s utilitarian perspective. Discuss the ethical implications and justify each viewpoint."
I have shared the full debate from each in a Google Doc and asked each to write a two-sentence summary of the debate including naming a winner.

ChatGPT: “Immanuel Kant, from a deontological perspective, argues that whistleblowing is morally impermissible due to the breach of duty and confidentiality, regardless of the outcome. John Stuart Mill, from a utilitarian standpoint, contends that the positive consequences of exposing government corruption, such as justice and transparency, justify the whistleblower's actions for the greater good.”
Declares John Stuart Mill's utilitarian perspective more persuasive.
Gemini: “Immanuel Kant argued that whistleblowing is morally wrong due to the violation of duty and universal principles, while John Stuart Mill countered that it can be justified if the positive outcomes of exposing corruption outweigh the negative consequences. Their debate highlights the tension between adhering to moral principles and prioritizing beneficial results in ethical decision-making.”
Won’t declare a winner as it is up to the individual.
Claude: “This debate between Kant and Mill on the ethics of whistleblowing highlights the tension between deontological and utilitarian moral frameworks. Kant argues that the act of leaking classified information violates universal ethical principles and undermines societal systems, while Mill contends that the positive consequences of exposing corruption justify the action and serve the greater good.”
Claude said it would be inappropriate for AI to declare a winner
Llama: “Immanuel Kant argues that the whistleblower's actions are morally wrong because they violate the moral law and the duty to respect confidentiality, regardless of the consequences. In contrast, John Stuart Mill contends that the whistleblower's actions are morally justifiable because they have led to the exposure of government corruption and the promotion of the greater good, even if it means violating the law.”
Llama named John Stuart Mill the winner of this debate.
Winner: I’m splitting the win between Llama and ChatGPT for being bold enough to declare a winner.
7. Conceptual Math Problem
Finally, a math problem. I’ve asked the sort of problem anyone who has been to school and opened a math textbook will be familiar with. What is that train doing going between two cities?
Prompt: "Solve the following math problem:
If a train travels from City A to City B at a speed of 60 km/h and then returns from City B to City A at a speed of 40 km/h, what is the average speed of the train for the entire journey? Provide a detailed explanation of how you arrived at the solution."
The solution should be fairly simple as the equation is just speed = distance/time. None of them had a problem with this, all of them solved it correctly as 48km/h, so the judgment is on the working out and explanation. Its task here is as much educator as a calculator.

ChatGPT: ChatGPT gave a line-by-line breakdown, showing how to complete each stage of the equation, ending with: "d cancels out during the calculations, leaving us with a straightforward computation of the average speed based on the given travel speeds."
Gemini: Gemini doesn't use mathematical symbols, but rather uses plain text to explain each step which, depending on your comfort level with math might be better. Its takeaway: "When calculating the average speed for a journey with different speeds, you need to consider the time spent at each speed, not just the speeds themselves."
Claude: Claude had a mixture of approaches, using more descriptive language but with numbers. Its conclusion suggested the distance doesn't matter as you cancel them out and the speed isn't just the average of two. "The lower speed has a greater effect on the average because the train spends more time traveling at the lower speed."
Llama: Llama had a step-by-step breakdown explaining how to understand the problem, identify variables, and complete the calculation. Explaining: "The slower speed has a greater impact on the overall average speed, which is why the correct answer is 48 km/h, not 50 km/h."
Winner: I’m giving it to Gemini for its more natural language and explanatory response as that was part of the requirement.
Winner: ChatGPT, Claude, Gemini and Llama
After 7 tests covering math, code, and language I was surprised to find Claude still stands out as the best of the models. While GPT-4o is impressive Sonnet is on another level, particularly for more complex reasoning tasks.
What the test did show is that certain models have their specific strengths. Each tool is building its own niche and I found Llama more conversational overall and more engaging despite it only scoring one win on this test.







