
Meta recently released a study detailing its Llama 3 405B model training run on a cluster containing 16,384 Nvidia H100 80GB GPUs. The training run took place over 54 days and the cluster encountered 419 unexpected component failures during that time, averaging one failure every three hours. In half of the failure cases, GPUs or their onboard HBM3 memory were to blame.
As the old supercomputing adage goes, the only certainty with large-scale systems is failure. Supercomputers are extremely complex devices that use tens of thousands of processors, hundreds of thousands of other chips, and hundreds of miles of cables. In a sophisticated supercomputer, it's normal for something to break down every few hours, and the main trick for developers is to ensure that the system remains operational regardless of such local breakdowns.
The scale and synchronous nature of 16,384 GPU training make it prone to failures. If the failures aren't mitigated correctly, a single GPU failure can disrupt the entire training job, necessitating a restart. However, the Llama 3 team maintained over a 90% effective training time.
During a 54-day pre-training snapshot, there were 466 job interruptions, with 47 planned and 419 unexpected. Planned interruptions were due to automated maintenance, while unexpected ones mostly stemmed from hardware issues. GPU problems were the largest category, accounting for 58.7% of unexpected interruptions. Only three incidents required significant manual intervention; the rest were managed by automation.
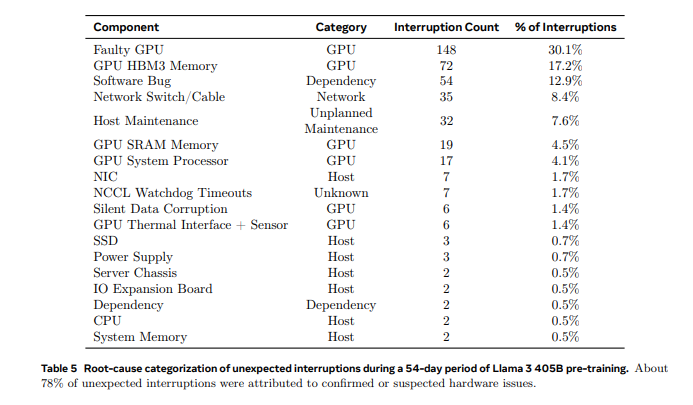
Out of 419 unexpected interruptions, 148 (30.1%) were caused by various GPU failures (including NVLink failures), whereas 72 (17.2%) were caused by HBM3 memory failures, which is not too surprising given that Nvidia's H100 GPUs consume around 700W and suffer a lot of thermal stress. Interestingly, only two CPUs failed in 54 days.
But while GPUs are the most important components that also happen to be fragile, 41.3% of unexpected interruptions were caused by numerous factors, including software bugs, network cables, and network adapters.
To enhance efficiency, Meta's team reduced job startup and checkpointing times and developed proprietary diagnostic tools. PyTorch’s NCCL flight recorder was used extensively to quickly diagnose and resolve hangs and performance issues, particularly related to NCCLX. This tool captures collective metadata and stack traces, aiding in swift problem resolution.
NCCLX played a crucial role in failure detection and localization, especially for NVLink and RoCE-related issues. The integration with PyTorch allowed for monitoring and automatic timeout of communication stalls caused by NVLink failures.
Straggling GPUs, which can slow down thousands of other GPUs, were identified using specialized tools. These tools prioritized problematic communications, enabling effective detection and timely resolution of stragglers, which ensured that slowdowns were minimized, maintaining overall training efficiency.
Environmental factors, such as mid-day temperature fluctuations, impacted training performance by causing a 1-2% variation in throughput. The dynamic voltage and frequency scaling of GPUs were affected by these temperature changes, though it wasn't a big problem.
Yet another challenge experienced by the Llama 3 405B LLM training team is simultaneous power consumption changes of tens of thousands of GPUs, which stresses their data center's power grid. These fluctuations, sometimes in the tens of megawatts, stretched the grid's limits, which means that Meta has to ensure that its data centers have enough power.
Considering the fact that a 16,384 GPU cluster experienced 419 failures in 54 days (7.76 times per 24 hours, or a failure every three hours), we can only wonder how often xAI's cluster containing 100,000 H100 GPUs, a six-fold increase in the number of components that could fail, will experience a failure.







