
While Intel's Habana Gaudi offers somewhat competitive performance and comes with the Habana SynapseAI software package, it still falls short compared to Nvidia's CUDA-enabled compute GPUs. This, paired with limited availability, is why Gaudi hasn't been as popular for large language models (LLMs) like ChatGPT.
Now that the AI rush is on, Intel's Habana is seeing broader deployments. Amazon Web Services decided to try Intel's 1st Generation Gaudi with PyTorch and DeepSpeed to train LLMs, and the results were promising enough to offer DL1 EC2 instances commercially.
Training large language models (LLMs) with billions of parameters presents challenges. They need specialized training techniques, considering the memory limitations of a single accelerator and the scalability of multiple accelerators working in concert. Researchers from AWS used DeepSpeed, an open-source deep learning optimization library for PyTorch designed to mitigate some of the LLM training challenges and accelerate model development and training, and Intel Habana Gaudi-based Amazon EC2 DL1 instances for their work. The results they achieved look very promising.
The researchers built a managed compute cluster using AWS Batch, comprising 16 dl1.24xlarge instances, each with eight Habana Gaudi accelerators and 32 GB of memory and a full mesh RoCE network between cards with a total bi-directional interconnect bandwidth of 700 Gbps each. Also, the cluster was equipped with four AWS Elastic Fabric Adapters with a total of 400 Gbps interconnect between nodes.
On the software side of matters, the researchers used DeepSpeed ZeRO1 optimizations for pre-training the BERT 1.5B model with various parameters. The goal was to optimize training performance and cost-effectiveness. To ensure model convergence, hyperparameters were adjusted, and the effective batch size per accelerator was set to 384, with micro-batches of 16 per step and 24 steps of gradient accumulation.
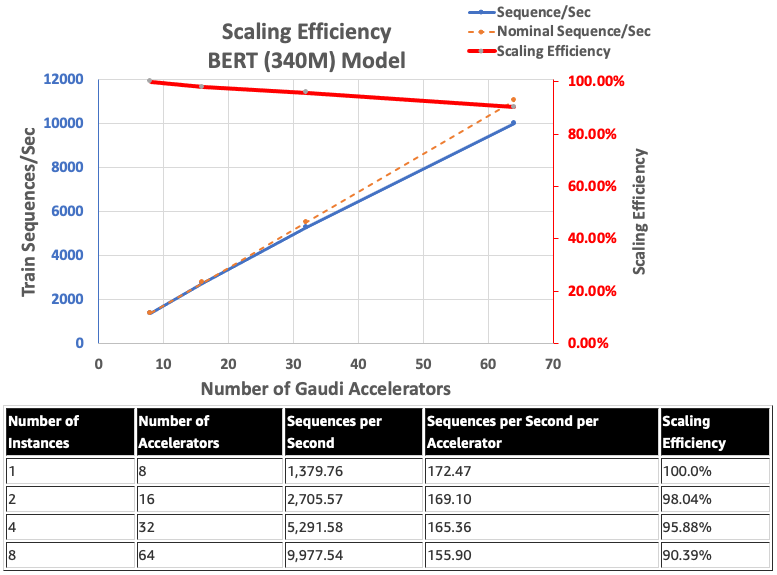
Intel HabanaGaudi's scaling efficiency tends to be relatively high and never drops below 90%, with eight instances and 64 accelerators running a BERT 340 million model.
Meanwhile, using Gaudi's native BF16 support, AWS researchers reduced memory size requirements and increased training performance compared to the FP32 to enable BERT 1.5 billion models. They achieved a scaling efficiency of 82.7% across 128 accelerators using DeepSpeed ZeRO stage 1 optimizations for a BERT model with 340 million to 1.5 billion parameters.
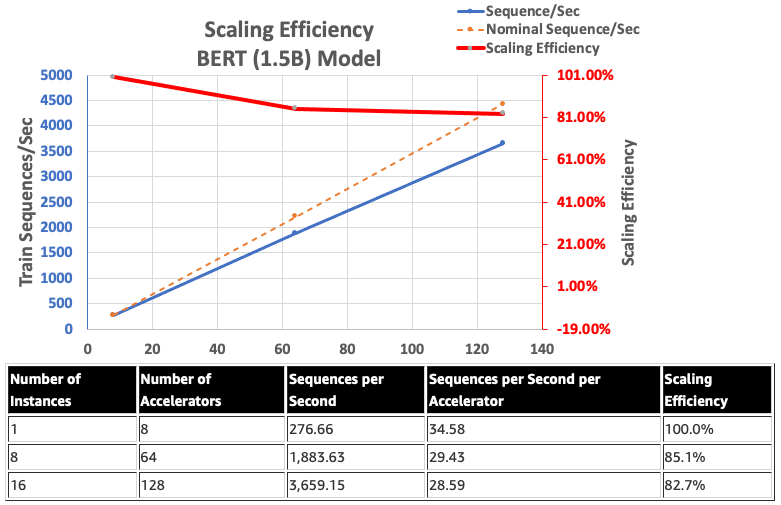
In general, AWS researchers found that using proper Habana SynapseAI v1.5/v1.6 software with DeepSpeed and multiple Habana Gaudi accelerators, a BERT model with 1.5 billion parameters could be pre-trained within 16 hours, reaching convergence on a network of 128 Gaudi accelerators, achieving a scaling efficiency of 85%. The architecture can be evaluated in the AWS Workshop.







