Most of us take speaking for granted. You open your mouth, words come out, and people listen to you. However, in some cases, such as at a noisy construction site, during a military operation, or in a medical condition that has taken away someone's voice, that simple exchange falls apart. Microphones have long been the answer, but even the best of them can’t handle extreme noise. Now, a team of South Korean researchers may have found a way around the problem altogether, and it doesn’t need your voice at all.
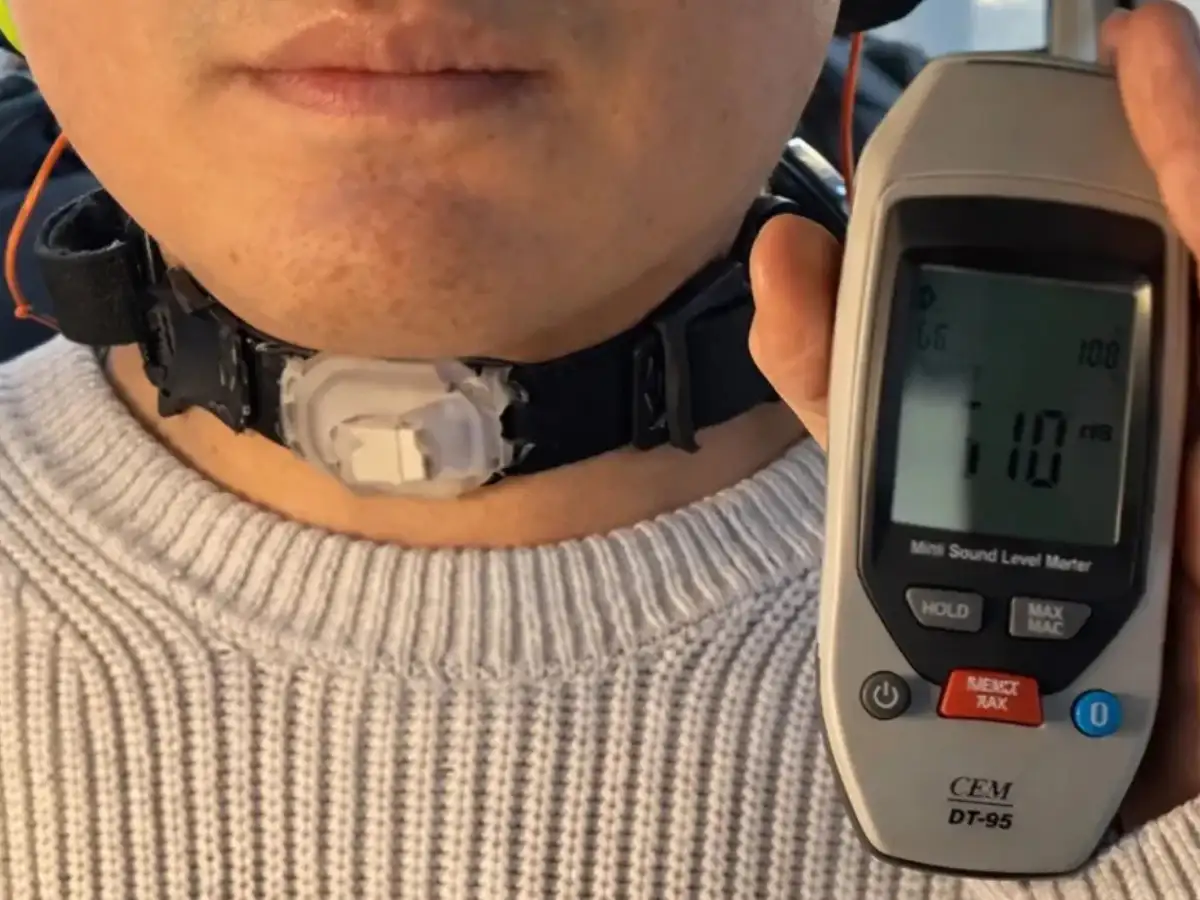
Researchers at Pohang University of Science and Technology (POSTECH) have developed a wearable neckband that can detect tiny movements in your neck muscles when you mouth words and translate them into speech in your own voice. The research shows you don’t have to make a sound with this device. It only needs you to try it.
How it really works
The basic idea is that whenever you speak, or even try to speak, the muscles and skin in your neck move in subtle but predictable ways. Those tiny motions add up to what researchers call a “movement map,” a kind of silent fingerprint for each word you make.
POSTECH's neckband is made of soft silicone and has a tiny camera and motion sensors. It follows those skin deformations in real time, sending the patterns into an AI model that determines the intended word. Once it is detected, the system turns it into audio using the user’s pre-recorded voice. Training the voice model takes less than 10 minutes, and then the device talks in your cadence, your tone, your character.
In testing, the neckband correctly identified 85.8% of a vocabulary of 26 words. That number drops quite a bit when the user is on the move, which is one of the hurdles the team is still working through, but it really shone in one area: background noise.
The problem of a noisy environment
This is where it’s interesting for everyday applications. During testing, the system showed a reliable signal-to-noise ratio of around 90 decibels compared to white noise, comparable to a busy construction site and better than the performance of current commercial systems in similar conditions. In other words, it was clear amid all the surrounding chaos.
That goes a long way in industries where communication breakdowns have real consequences. Research supports this, and garbled messages are more than an annoyance to first responders, manufacturing floor workers, aviation crews, and military personnel. Researchers from the University of Cambridge published a study on wearable silent speech interfaces in 2025. They found that systems that decode speech from muscle signals rather than audio could be of great benefit in environments with a lot of noise or interference, achieving up to 96% accuracy on common commands in controlled tests.
Beyond the clinic
The POSTECH device was initially conceived with a medical purpose: to return speech to those who have lost it, like laryngectomy patients or people with speech disorders. According to the research leader, Professor Sung-Min Park, the technology is hoped to speed up the day when patients with speech disorders can get their voices back.
There is more potential. The research team then discusses applications for industrial facilities, emergency response, aviation, and even everyday quiet environments such as libraries or open-plan offices, where it is not always practical to speak aloud.
Still in its early days
Just to clarify, this isn’t something you are going to see in a store anytime soon. The implementation currently uses a fixed vocabulary of 26 words; accuracy drops when the user is moving, and the system needs to be tested further with a wider range of people and speech patterns. The POSTECH team intends to increase the vocabulary and enhance the natural movement of the device.
The direction, however, is striking. We used to think of AI as something that enhances audio: removing noise, clarifying voices, and transcribing speech. This flips that entirely. It asks: what if we skipped the sound altogether?
That’s a question worth paying attention to for the millions of Americans who work in loud settings, depend on assistive communication, or simply want a cleaner way to be heard.







