In our current information/data age, the storage and protection of data is an extremely important part of any business venture. The degree of digital data being produced, globally, has long been outpacing the amount of storage available—irrespective of the medium onto which that data is stored.
Cloud, obviously, is currently taking first place on the storage agenda given its flexibility and user expectations, however, there is a relatively new means for data storage that arrived several years ago and is now taking on some very different new perspectives.
We’re speaking of “DNA data storage”—yes “DNA” or more formally known as deoxyribonucleic acid—that tongue-twisting, nearly impossible to write term we learned back in high-school physics classes. That is, this storage concept is the enabling of molecular-level data storage into DNA molecules that leverages biotechnology advances in synthesizing, manipulating and sequencing DNA to develop archival storage.
The next few paragraphs will take a very basic overview of the chemical make-up of elements in molecular science. You don’t necessarily need to be a biochemist to fully understand this section, but you can quickly see how this leads into the LOCO coding structure and error detection properties which are essential for DNA data storage.
The term “LOCO,” or in this case D-LOCO (for DNA-LOCO) means Lexicographically-Ordered Constrained Codes, which are “line codes that make it possible to mitigate interference, prevent short pulses, and will generate streams of bipolar signals with direct-current (DC) powered content” through the “employment of balancing.” These principles are found in magnetic-recording (MR) devices, in Flash devices, in optical recording, and in certain computer standards.
Ten Terabytes on a PinHead?
Exploring the intersection of information technology and molecular biology has created a scientific means for the storage of over 10 terabytes of data in the space of a faint smear less than the space of 0.25 x 0.25 inches (0.0625 sq-inches). Comparatively, from American theoretical physicist Richard P. Feynman’s dissertation (December 1959), he theorized how to manipulate, manufacture, and control things on a micro-level (small) scale.
From a coding perspective, this micro/nano technology practice dates back to work in 1948 whereby the density of data is increased through the use of such “constrained codes” which resulted in increased storage density in MR (i.e., magnetic recording). Such practices are still widely in use today which mitigate interference in today’s two-dimensional MR systems.
Functional Artificial Objects
The science of this DNA storage remains somewhat experimental and is very much an ongoing research project of well recognized coding and by biochemistry experts throughout the world.
For example, using in-silico (i.e., experimentation performed by computer) and wet lab experiments, the Molecular Information Systems Lab (MISL) at the University of Washington (UW) in partnership with UW Computer Science, Electrical Engineering, and Microsoft Research, have brought together faculty, students and research scientists with expertise in computer architecture, programming languages, synthetic biology, and biochemistry to enable the use of DNA as a high-density, durable and easy-to-manipulate storage medium.
Historically, the idea for DNA digital data storage began around 1959 when Feynman (see sidebar) outlined—at the annual meeting of the American Physical Society at the California Institute of Technology—the prospects of artificial objects of the microcosm and biological microcosms having similar or even more extensive capabilities in his paper “There’s Plenty of Room at the Bottom.”
Another book worthy of further understanding is by Ed Regis (April 1996) called “Nano: The Emerging Science of Nanotechnology.” Nano tells the gripping story of how K. Eric Drexler and other scientists pioneered this emerging science. It explores what molecular nanotechnology could mean for our future as it was presented to scientists and congressional representatives on June 26, 1952. These concepts were further recognized by future Vice President Al Gore, who presided over the presentations to the panel in 1996.
Biochemical DNA & RNA
Functionality wise, DNA digital data storage is a process that encodes and decodes binary data to and from synthesized strands of DNA. Arguably, there is enormous potential resulting from its high storage density, but the practical use of DNA data storage is (currently) “severely limited” due to its high cost and very slow read and write times.
In biochemistry, the depth of this topic is ginormous and well beyond the details presented in this article. However, the basics of what composes the DNA-elements include some of the following micro-biological concepts and principles:
A nucleoside is comprised of a nucleobase (which function as the fundamental units of the genetic code and five-carbon sugar (ribose or 2-deoxyribose). Nucleobases are nitrogen-containing biological compounds that form nucleosides, which, in turn, are components of nucleotides, with all of these monomers formulate (i.e., the constitute) the basic building blocks of nucleic acids.
A nucleotide is “a compound consisting of a nucleoside linked to a phosphate group.” The nucleotide is the molecular building block of nucleic acids, RNA and DNA, both of which are essential biomolecules within all life-forms on Earth. The four bases used in DNA are adenine (A), cytosine (C), guanine (G) and thymine (T). In RNA, the base uracil (U) takes the place of thymine (T).
Ribonucleic acid (RNA) is a molecule that is present in the majority of living organisms and viruses. Like DNA, it too is made up of nucleotides—which are ribose sugars attached to nitrogenous bases and phosphate groups. This is a nucleic acid is found in all living cells that have structural similarities to deoxyribonucleic acid (DNA).
In Fig. 1 the makeup of RNA (left) and DNA (middle) present in most living organisms on our planet and referenced to those 4-ary (i.e., a group or set of four [quad/quadary] data elements—in this case the “nucleobases”), are used in the coding of DNA/RNA for storage. The CG-content is depicted in the smaller diagram (far right).
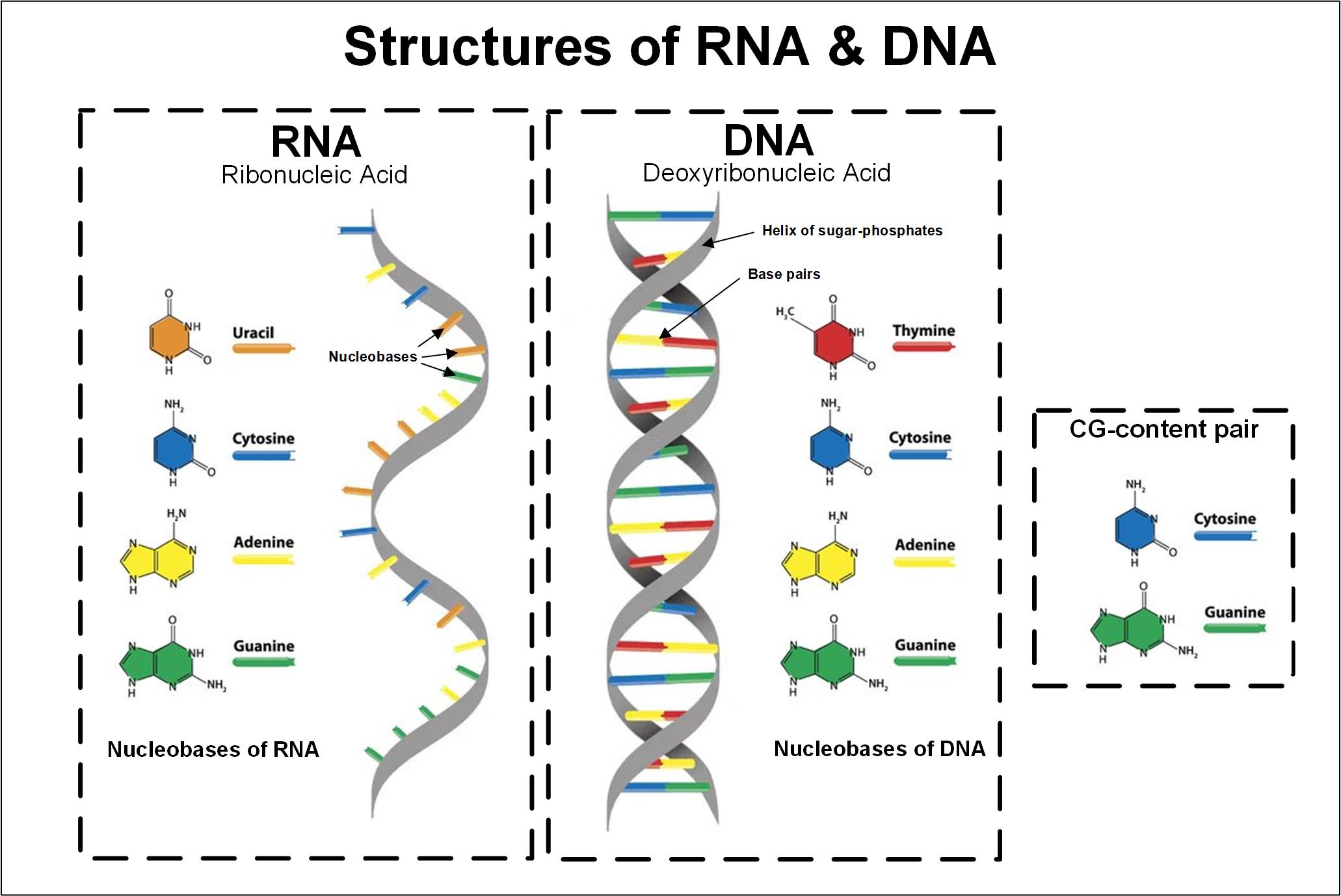
From the theoretic information perspective, strands of DNA serve as a storage medium for 4-ary data over the alphabet {A, T, G, C}. The “alphabet” referenced here aligns with the four components of the DNA nucleobases mentioned in the biochemical descriptions above and as shown in the diagram of Fig. 1.
Cold Data
DNA is part of the next-generation technology that can support storing mass “cold-data” (i.e., “archival”) or information which does not require regular or continuous access. Pools of synthetic DNA are being proposed as a potential medium aimed at archival (long term) storage purposes. Through the use of coding and data processing, errors are prevented during the biochemical processing proceeding the development of the DNA strands.
For long term storage, all of the data sequences must contain limited runs of identical symbols and a balanced ratio (percentage) of A-to-T (Adenine to Thymine) and G-to-C (Guanine to Cytosine) nucleotides. These compositions are referred to as “constrained codes,” which are a class of nonlinear codes that by proper processing, eliminate a chosen set of “forbidden patterns” from the codeword sets.
Promises and Encumbrances
DNA data storage promises formidable information density, long-term durability, and ease of replicability. However, information in this intriguing storage technology might also become corrupted. Experiments have revealed that DNA sequences with long homopolymers and/or with lower guanine-cytosine (i.e., “GC-content,” see inset of Fig. 1) are notably more subject to errors upon or when moved into DNA-storage.
Guanine-cytosine content is the percentage of nitrogenous bases in DNA or RNA molecules which are either guanine (G) or cytosine (C). A higher GC-content level indicates a higher melting temperature. GC-content should be in the 30%-80% range, with 50-55% being ideal; and the GC content influences the evolution of proteins because of energy cost. A brief summary comparison of RNA vs. DNA are shown in Fig 2 (noting the CG-content in blue).

One probably never realized the complexities in storage beyond how magnetic areal density or how the fluctuation of magnetic energy relates to the pickup head of a spinning magnetic (hard) disk drive; but storage density will always need to increase if we’re going to sustain this ever-growing thirst for digital data.
When or if DNA data storage becomes prominent is still a vision into the future, but it is being promoted by companies including American companies Illumina, Microsoft, Iridia, Twist Bioscience, Catalog and Thermo Fisher Scientific. According to Markets and Markets, the DNA data storage market is projected to grow from $76 million in 2024 to $3.3 billion—growing at a CAGR of 87.7%—by 2030.