
The best graphics cards aren't just for gaming, especially not when AI-based algorithms are all the rage. Besides ChatGPT, Bard, and Bing Chat (aka Sydney), which all run on data center hardware, you can run your own local version of Stable Diffusion, Text Generation, and various other tools... like OpenAI's Whisper. The last one is our subject today, and it can provide substantially faster than real-time transcription of audio via your GPU, with the entire process running locally for free. You can also run it on your CPU, though the speed drops precipitously.
Note also that Whisper can be used in real-time to do speech recognition, similar to what you can get through Windows or Dragon NaturallySpeaking. We did not attempt to use it in that fashion, as we were more interesting in checking performance. Real-time speech recognition only needs to keep up with maybe 100–150 words per minute (maybe a bit more if someone is a fast talker). We wanted to let the various GPUs stretch their legs a bit and show just how fast they can go.
There are a few options for running Whisper, on Windows or otherwise. Of course there's the OpenAI GitHub (instructions and details below). There's also this Const-Me project, WhisperDesktop, which is a Windows executable written in C++. That uses DirectCompute rather than PyTorch, which means it will run on any DirectX 11 compatible GPU — yes, including things like Intel integrated graphics. It also means that it's not using special hardware like Nvidia's Tensor cores or Intel's XMX cores.
Getting WhisperDesktop running proved very easy, assuming you're willing to download and run someone's unsigned executable. (I was, though you can also try to compile the code yourself if you want.) Just grab WhisperDesktop.zip and extract it somewhere. Besides the EXE and DLL, you'll need one or more of the OpenAI models, which you can grab via the links from the application window. You'll need the GGML versions — we used ggml-medium.en.bin (1.42GiB) and ggml-large.bin (2.88GiB) for our testing.
You can do live speech recognition (there's about a 5–10 second delay, so it's not as nice as some of the commercial applications), or you can transcribe an audio file. We opted for the latter for our benchmarks. The transcription isn't perfect, even with the large model, but it's reasonably accurate and can finish way faster than any of us can type.
Actually, that's underselling it, as even the slowest GPU we tested (Arc A380) managed over 700 words per minute. That's substantially faster than even the fastest typist in the world, over twice as fast. That's also using the medium language model, which will run on cards with 3GB or more VRAM — the large model requires maybe 5GB or more VRAM, at least with WhisperDesktop. Also, the large model is roughly half as fast.
If you're planning to use the OpenAI version, note that the requirements are quite a bit higher, 5GB for the medium model and 10GB for the large model. Plan accordingly.
Whisper Test Setup
TOM'S HARDWARE TEST PC
Intel Core i9-13900K
MSI MEG Z790 Ace DDR5
G.Skill Trident Z5 2x16GB DDR5-6600 CL34
Sabrent Rocket 4 Plus-G 4TB
be quiet! 1500W Dark Power Pro 12
Cooler Master PL360 Flux
Windows 11 Pro 64-bit
Samsung Neo G8 32
GRAPHICS CARDS
Nvidia RTX 4090
Nvidia RTX 4080
Nvidia RTX 4070 Ti
Nvidia RTX 4070
Nvidia RTX 30-Series
AMD RX 7900 XTX
AMD RX 7900 XT
AMD RTX 6000-Series
Intel Arc A770 16GB
Intel Arc A750
Intel Arc A380
Our test PC is our standard GPU testing system, which comes with basically the highest possible performance parts (within reason). We did run a few tests on a slightly slower Core i9-12900K and found performance was only slightly lower, at least for WhisperDesktop, but we're not sure how far down the CPU stack you can go before it will really start to affect performance.
For our test input audio, we've grabbed an MP3 from this Asus RTX 4090 Unboxing that we posted last year. It's a 13 minute video, which is long enough to give the faster GPUs a chance to flex their muscle.
As noted above, we've run two different versions of the Whisper models, medium.en and large. We tested each card with multiple runs, discarding the first and using the highest of the remaining three runs. Then we converted the resulting time into words per minute — the medium.en model transcribed 1,570 words while the large model resulted in 1,580 words.
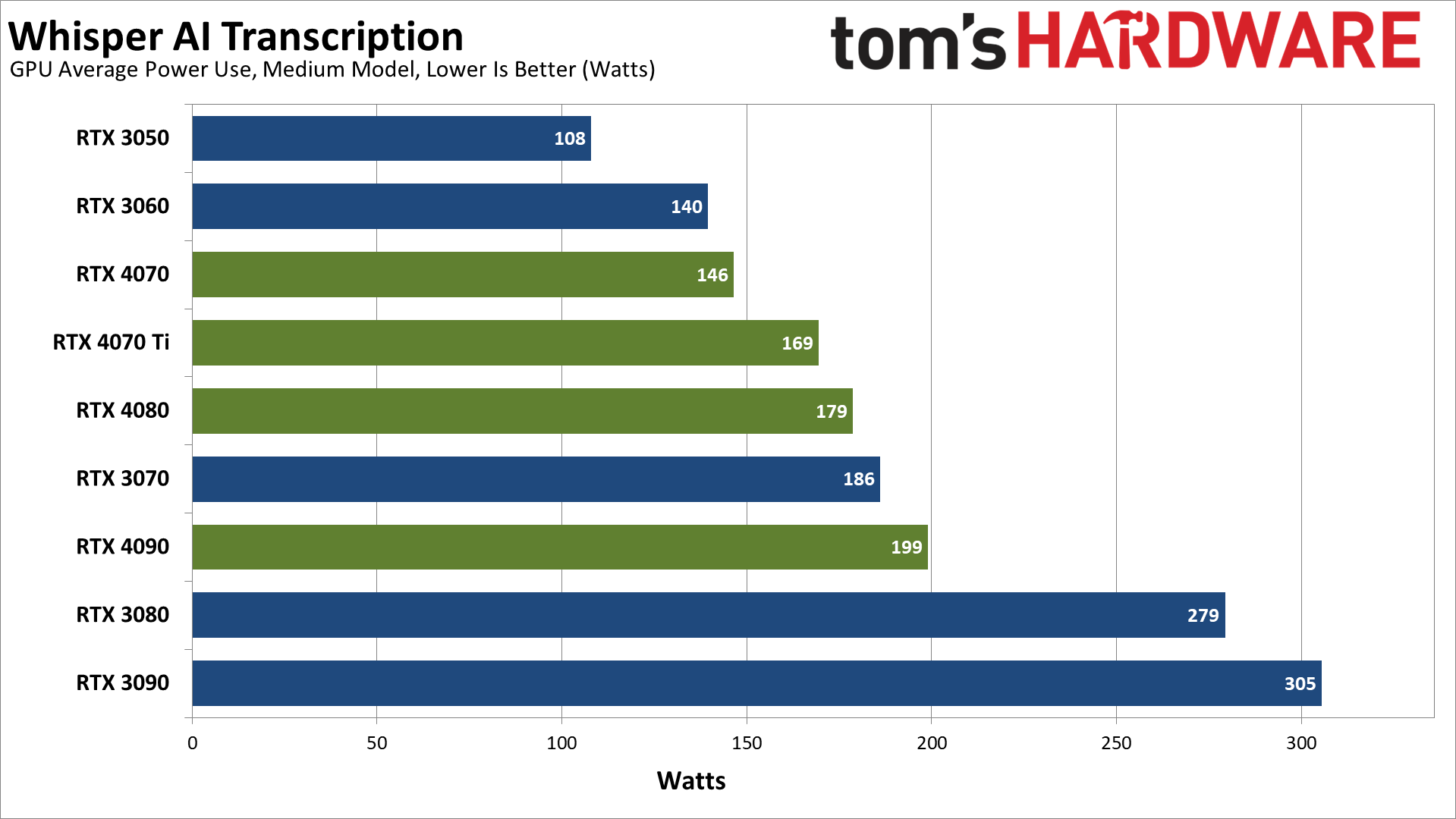
We also collected data on GPU power use while running the transcription, using an Nvidia PCAT v2 device. We start logging power use right before starting the transcription, and stop it right after the transcription is finished. The GPUs generally don't end up anywhere near 100% load during the workload, so power ends up being quite a bit below the GPUs' rated TGPs. Here are the results.
WhisperDesktop Medium Model, GPU Performance
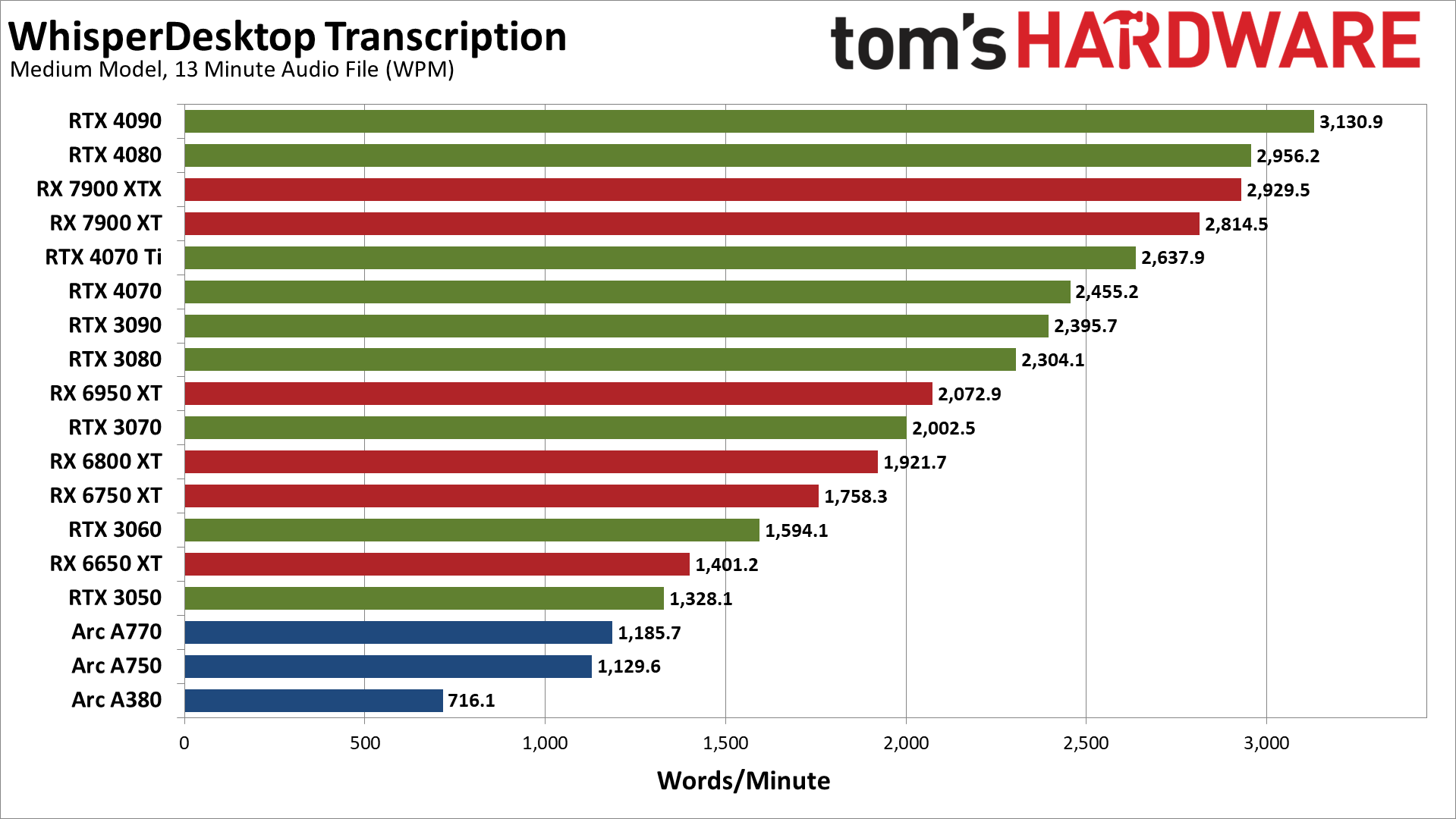
Our base performance testing uses the medium model, which tends to be a bit less accurate overall. There are a few cases where it got the transcription "right" while the large model was incorrect, but there were far more cases where the reverse was true. We're probably getting close to CPU limits as well, or at least the scaling doesn't exactly match up with what we'd expect.
Nvidia's RTX 4090 and RTX 4080 take the top two spots, with just over/under 3,000 words per minute transcribed. AMD's RX 7900 XTX and 7900 XT come next, followed by the RTX 4070 Ti and 4070, then the RTX 3090 and 3080. Then the RX 6950 XT comes in just ahead of the RTX 3070 — definitely not the expected result.
If you check our GPU benchmarks hierarchy, looking just at rasterization performance, we'd expect the 6950 XT to place closer to the 3090 and 4070 Ti, with the 6800 XT close to the 3080 and 4070. RX 6750 XT should also be ahead of the 3070, and the same goes for the 6650 XT and the 3060.
Meanwhile, Intel's Arc GPUs place at the bottom of the charts. Again, normally we'd expect the A770 and A750 to be a lot closer to the RTX 3060 in performance. Except, here we're looking at a different sort of workload than gaming, and potentially the Arc Alchemist architecture just doesn't handle this as well. It's also possible that there are simply driver inefficiencies at play.
Let's see what happens with the more complex large model.
WhisperDesktop Large Model, GPU Performance
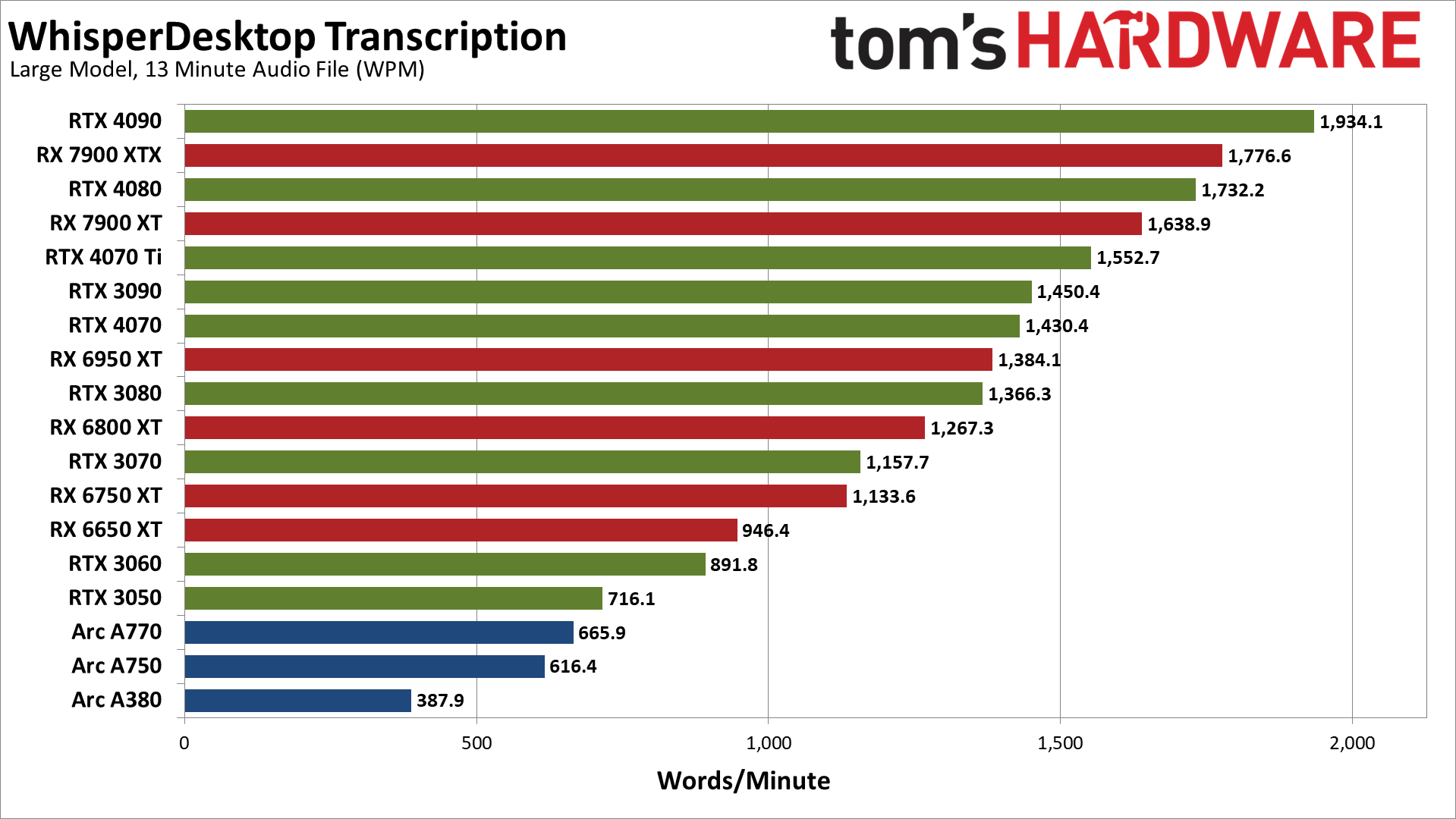
The large model definitely hits the GPU harder. Where the RTX 4090 was 2.36X faster than the RTX 3050 with the medium.en model, it's 2.7X faster using the large model. However, scaling is still nothing at all like we see in gaming benchmarks, where (at 1440p) the RTX 4090 is 3.7X faster than the RTX 3050.
Some of the rankings change a bit as well, with the 7900 XTX placing just ahead of the RTX 4080 this time. The 6950 XT also edges past the 3080, 6800 XT moves ahead of the 3070, and the 6650 XT moves ahead of the 3060. Intel's Arc GPUs still fall below even the RTX 3050, however.
It looks like the large L2 caches on the RTX 40-series GPUs help more here than in games. The gains aren't quite as big with the large model, but the 3080 for example usually beats the 4070 in gaming performance by a small amount, where here the 4070 takes the lead.
WhisperDesktop GPU Power Use and Efficiency
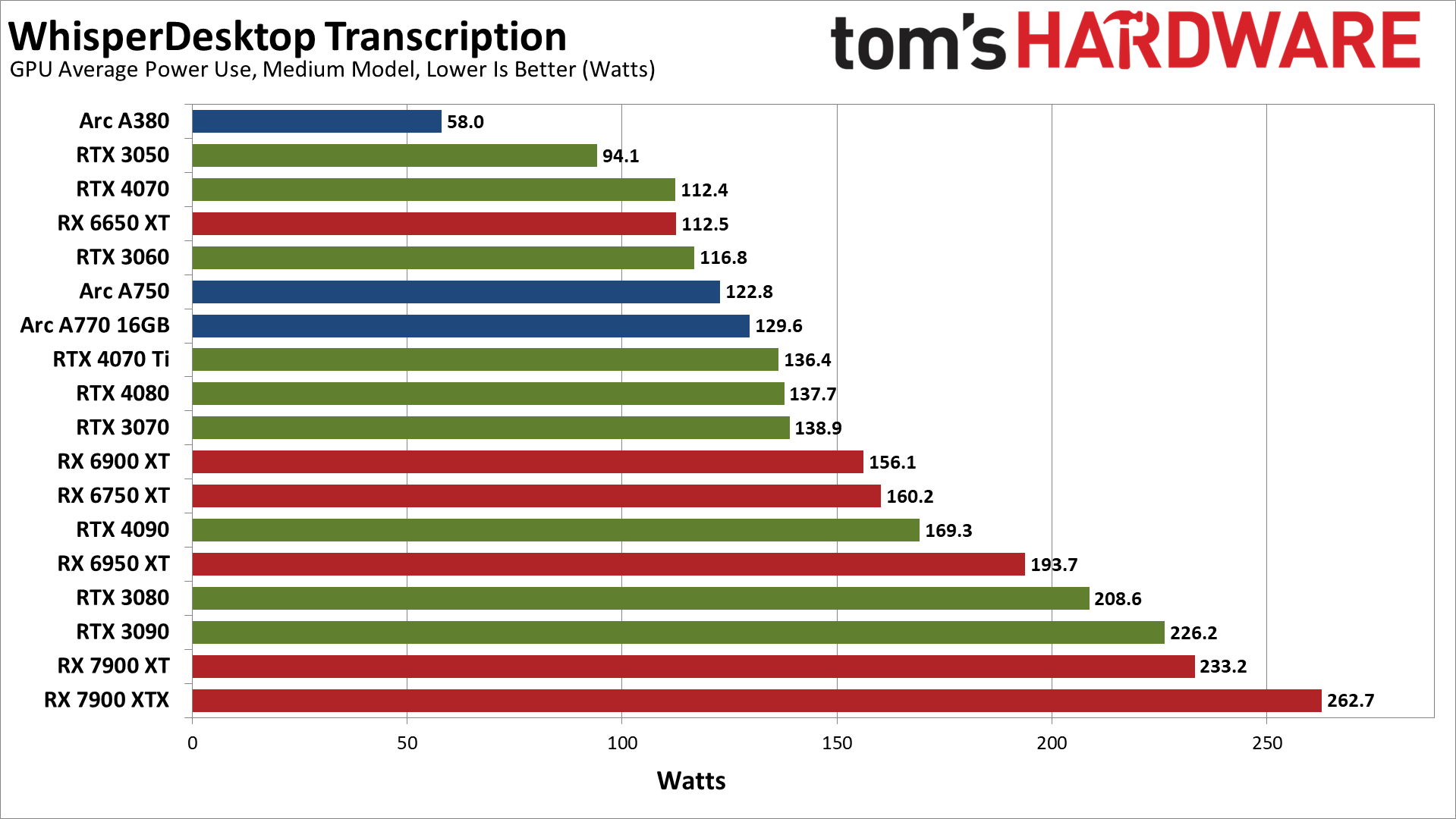
Finally, we've got power use while running the medium and large models. The large model requires more power on every GPU, though it's not a huge jump. The RTX 4090 for example uses just 6% more power. The biggest change we measured was with the RX 6650 XT, which used 14% more power. The RTX 4090 and RX 6950 XT increased power use by 10%, but some of the other GPUs only show a 1–3 precent delta.
One thing that's very clear is that the new Nvidia RTX 40-series GPUs are generally far more power efficient than their AMD counterparts. Conversely, the RTX 30-series (particularly 3080 and 3090) aren't quite as power friendly. AMD's new RX 7900 cards however end up being some of the biggest power users.
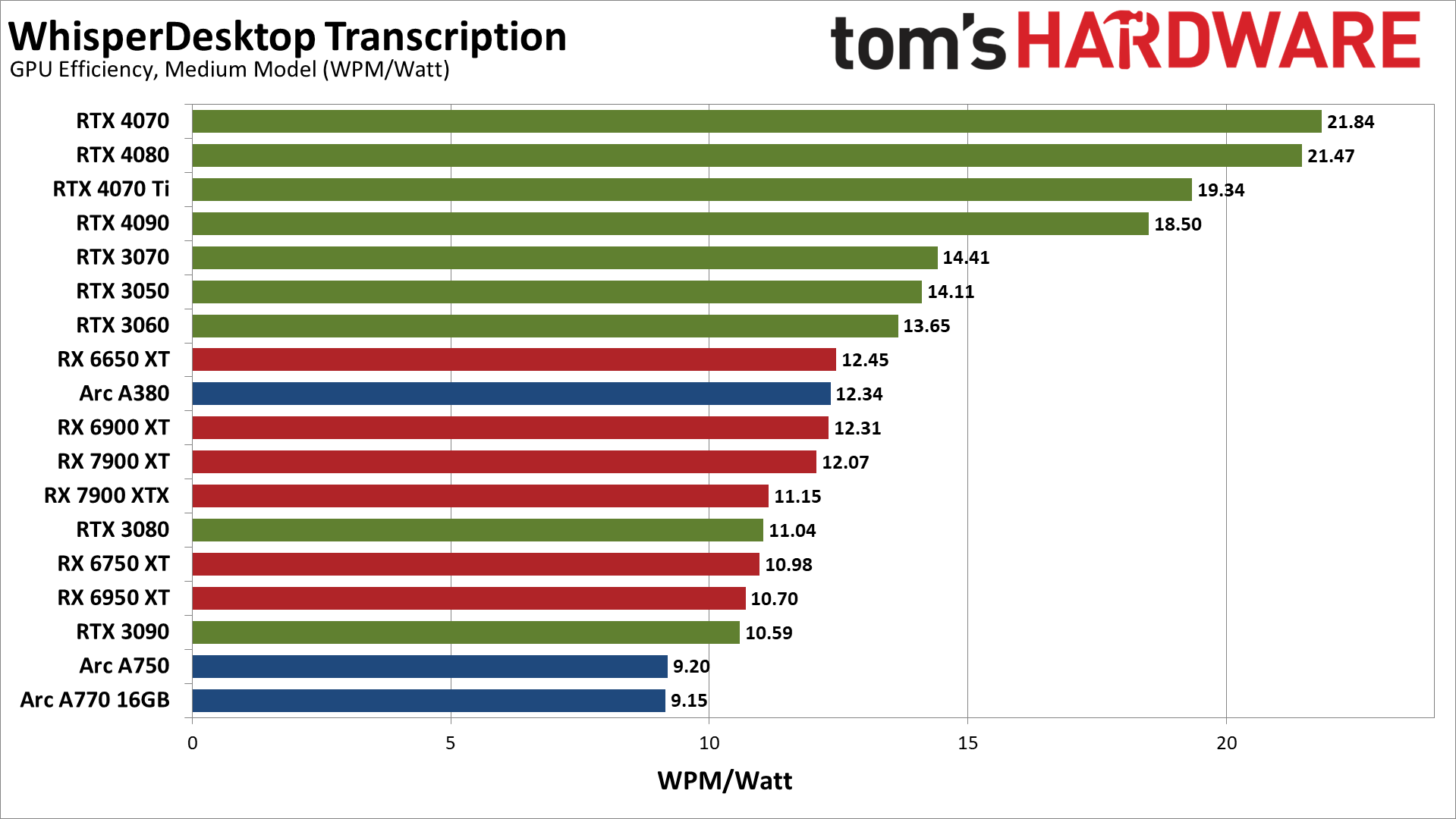
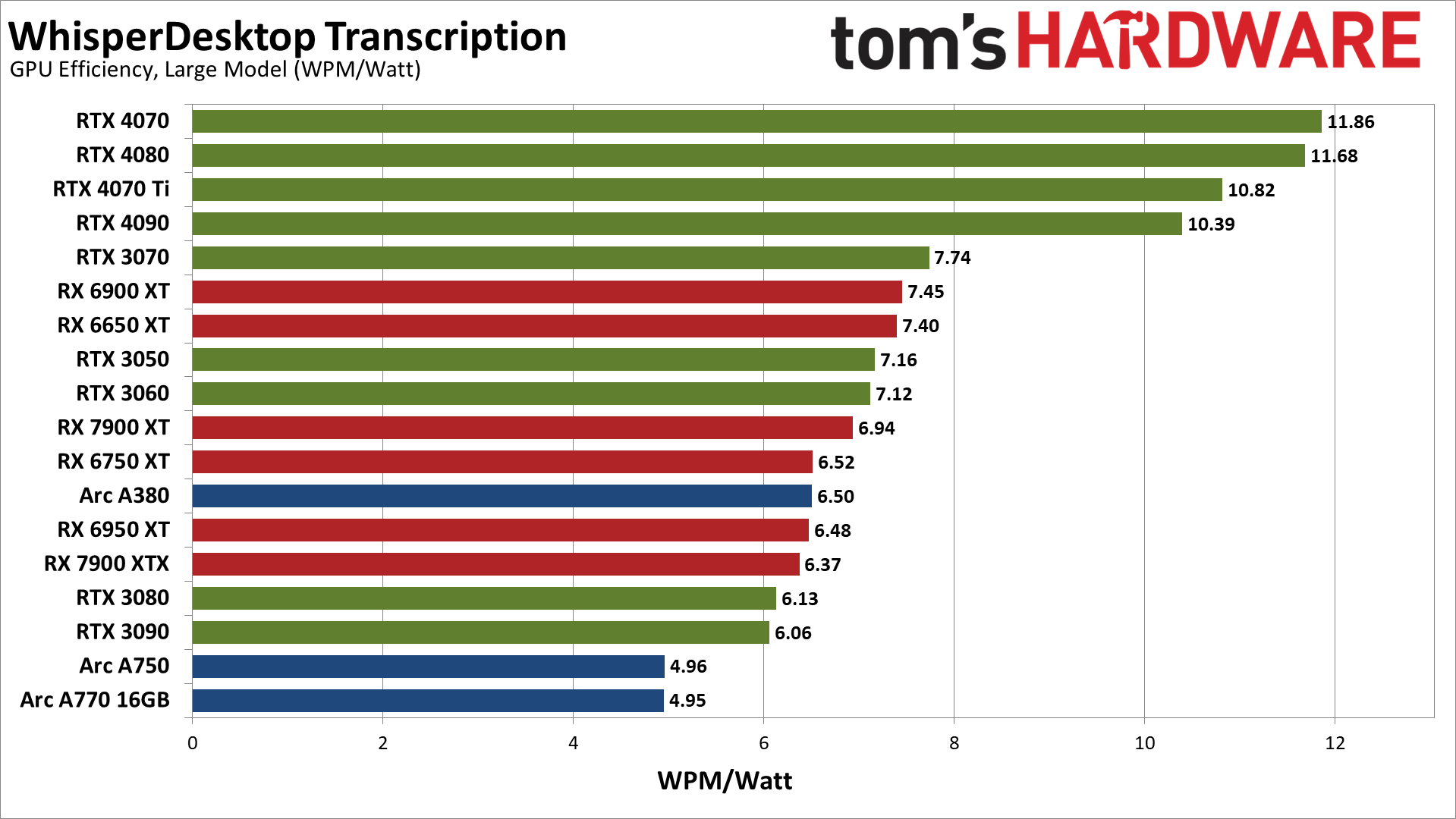
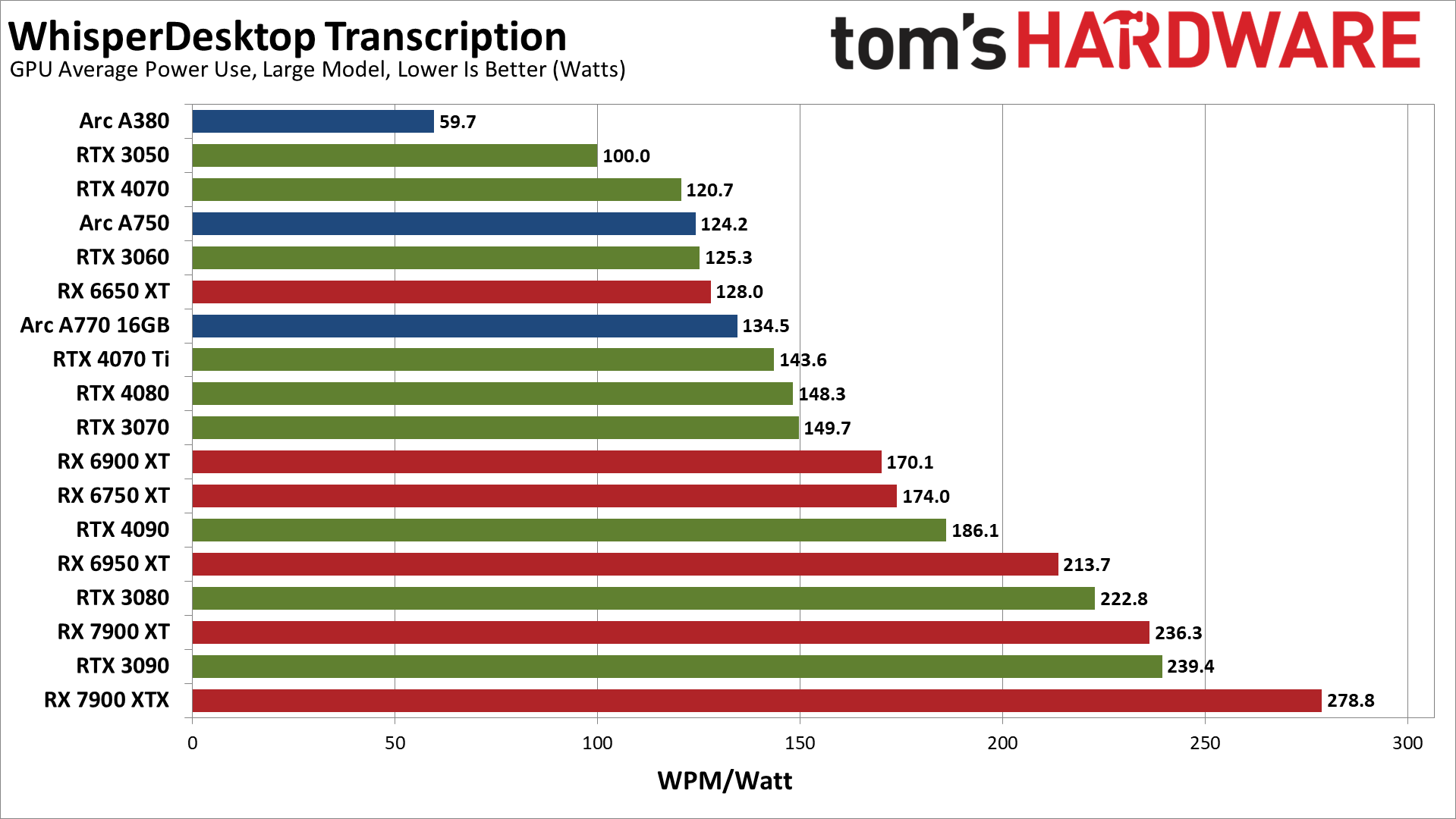
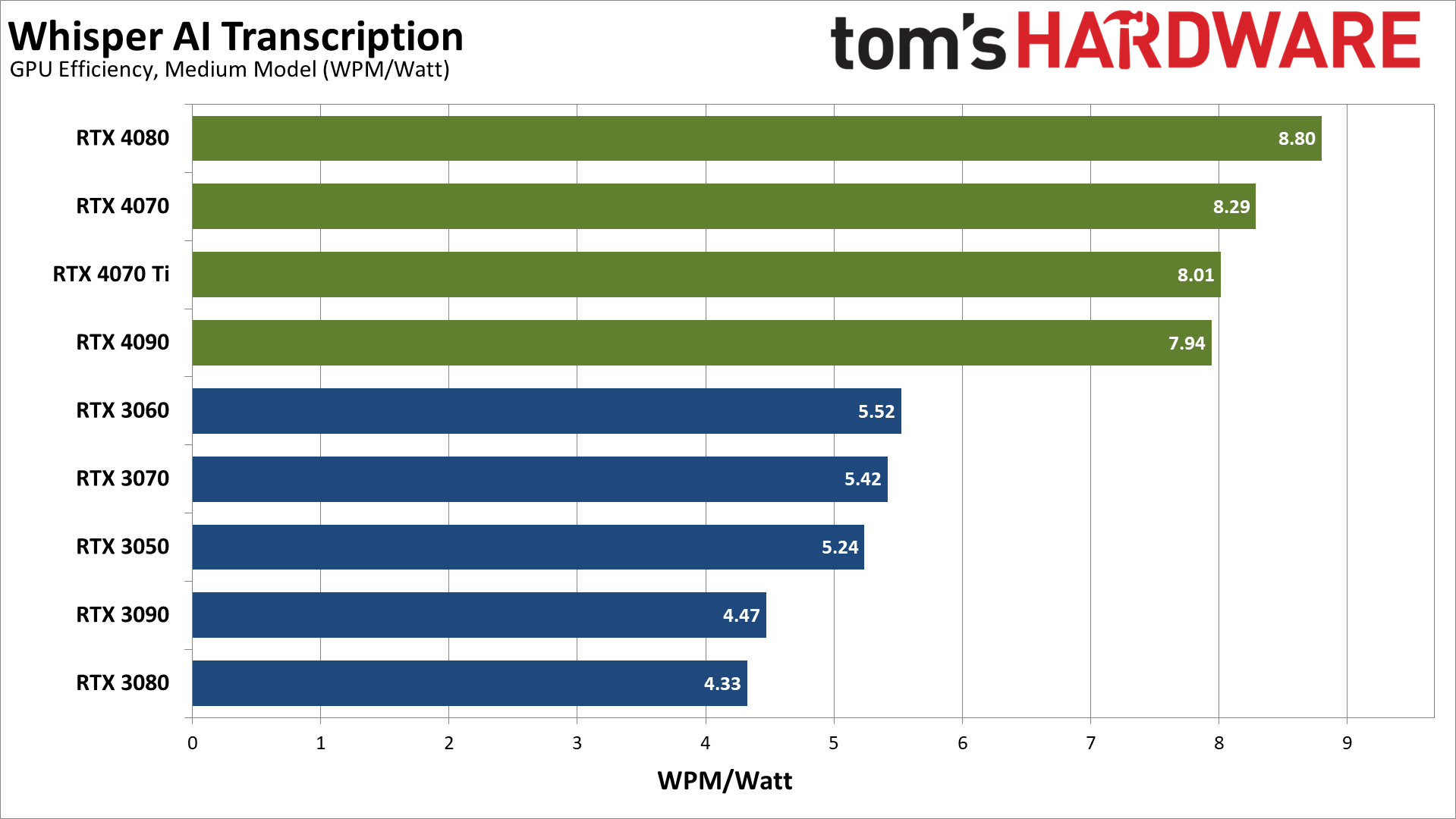
Converting to efficiency in words per minute per watt provides what is arguably the better view of the power and performance equation. The Ada Lovelace RTX 40-series cards end up being far more efficient than the competition. The lower tier Ampere RTX 30-series GPUs like the 3070, 3060, and 3050 come next, followed by a mix of RX 6000/7000 cards and the lone Arc A380.
At the bottom of the charts, the Arc A750 and A770 are the least efficient overall, at least for this workload. RTX 3090, RX 6950 XT, RX 6750 XT, RTX 3080, and RX 7900 XTX are all relatively similar at 10.6–11.2 WPM/watt.
Whisper OpenAI GitHub Testing
For what will become obvious reasons, WhisperDesktop is the preferred way of using Whisper on PCs right now. Not only does it work with any reasonably modern GPU, but performance tends to be much better than the PyTorch version from OpenAI, at least right now. If you want to try the official repository, however, we've got some additional testing results.
Getting Whisper running on an Nvidia GPU is relatively straightforward. If you're using Linux, you should check these instructions for how to get the CUDA branch running via ROCm on AMD GPUs. For now, I have opted to skip jumping through hoops and am just sticking to Nvidia. (Probably just use WhisperDesktop for AMD and Intel.)
Here are our steps for Nvidia GPUs, should you want to give it a shot.
1. Download and install Miniconda 64-bit for Windows. (We used the top link on that page, though others should suffice.)
2. Open a Miniconda prompt (from the Start Menu).
3. Create a new conda environment for Whisper.
conda create -n Whisper4. Activate the environment.
conda activate Whisper5. Install a whole bunch of prerequisites.
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia ffmpegNote: This will take at least several minutes, more depending on your CPU speed and internet bandwidth. It has to download and then compile a bunch of Python and other packages.
6. Download OpenAI's Whisper.
pip install -U openai-whisper7. Transcribe an audio file, alternatively specifying language, model, and device. We're using an Nvidia GPU with CUDA support, so our command is:
whisper.exe [audiofile] --model medium.en --device cudaIf you want a potentially better transcription using bigger model, or if you want to transcribe other languages:
whisper.exe [audiofile] --model large --device cuda --language enThe first time you run a model, it will need to be downloaded. The medium.en model is 1.42GiB, while the large model is 2.87GiB. (The models are stored in %UserProfile%\.cache\Whisper, if you're wondering.)
There's typically a several second delay (up to maybe 10–15 seconds, depending on your GPU) as Python gets ready to process the specified file, after which you should start seeing timestamps and transcriptions appear. When the task is finished, you'll also find plain text, json, SRT, TSV, and VTT versions of the source audio file, which can be used as subtitles if needed.
Whisper PyTorch Testing on Nvidia GPUs
Our test PC is the same as above, but this time the CPU appears to be a bigger factor. We ran a quick test on an older Core i9-9900K with an RTX 4070 Ti and it took over twice as long to finish the same transcription as with the Core i9-13900K, so CPU bottlenecks are very much a reality with the faster Nvidia GPUs on the PyTorch version of Whisper.
We should note here that we don't know precisely how all the calculations are being done in PyTorch. Are the models leveraging the tensor core hardware? Most likely not. Calculations could be using FP32 as well, which would be a pretty big hit to performance compared to FP16. In other words, there's probably a lot of room for additional optimizations.
As before, we're running two different versions of the Whisper models, medium.en and large (large-v2). The 8GB cards in our test suite were unable to run the large model using PyTorch, and the larger model puts more of a load on the GPU, which means the CPU becomes a bit less of a factor.
We created a script to measure the amount of time it took to transcribe the audio file, including the "startup" time. We also collected data on GPU power use while running the transcription, using an Nvidia PCAT v2 device. Here are the results.
Whisper PyTorch Medium Model, GPU Performance
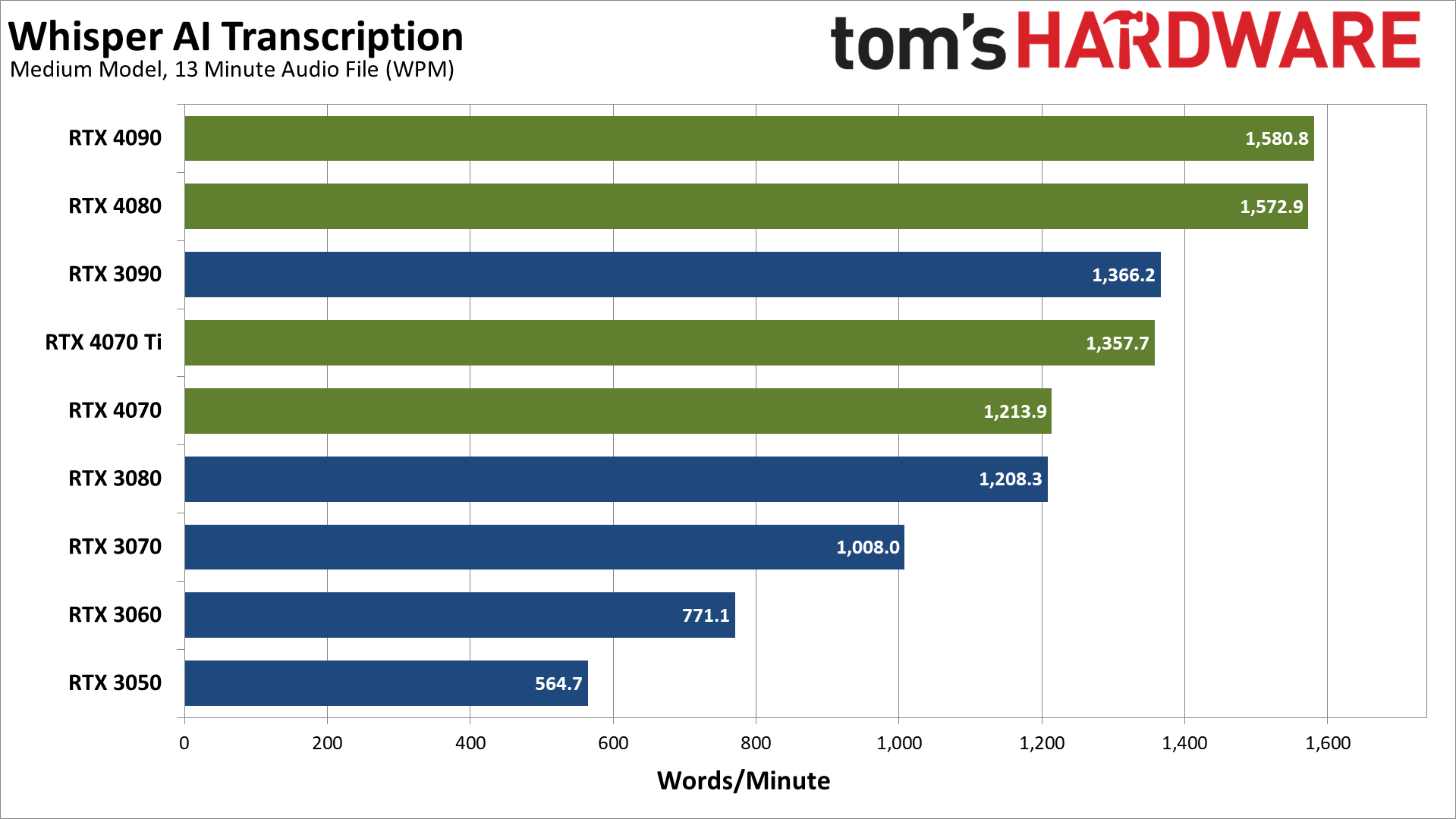
Like we said, performance with the PyTorch version (at least using the installation instructions above) ends up being far lower than with WhisperDesktop. The fastest GPUs are about half the speed, dropping from over 3,000 WPM to a bit under 1,600 WPM. Similarly, the RTX 3050 went from 1,328 WPM to 565 WPM, so in some cases PyTorch is less than half as fast.
We're hitting CPU limits as you can tell by how the RTX 4090 and RTX 4080 deliver essentially identical results. Yes, the 4090 is technically 0.5% faster, but that's margin of error.
Moving down the chart, the RTX 3090 and RTX 4070 Ti are effectively tied, and the same goes for the RTX 4070 and RTX 3080. Each step is about 10–15 percent slower than the tier above it, until we get to the bottom two cards. The RTX 3060 is 24% slower than the RTX 3070, and then the RTX 3050 is 27% slower than the 3060.
Let's see what happens with the more complex large model.
Whisper PyTorch Large Model, GPU Performance
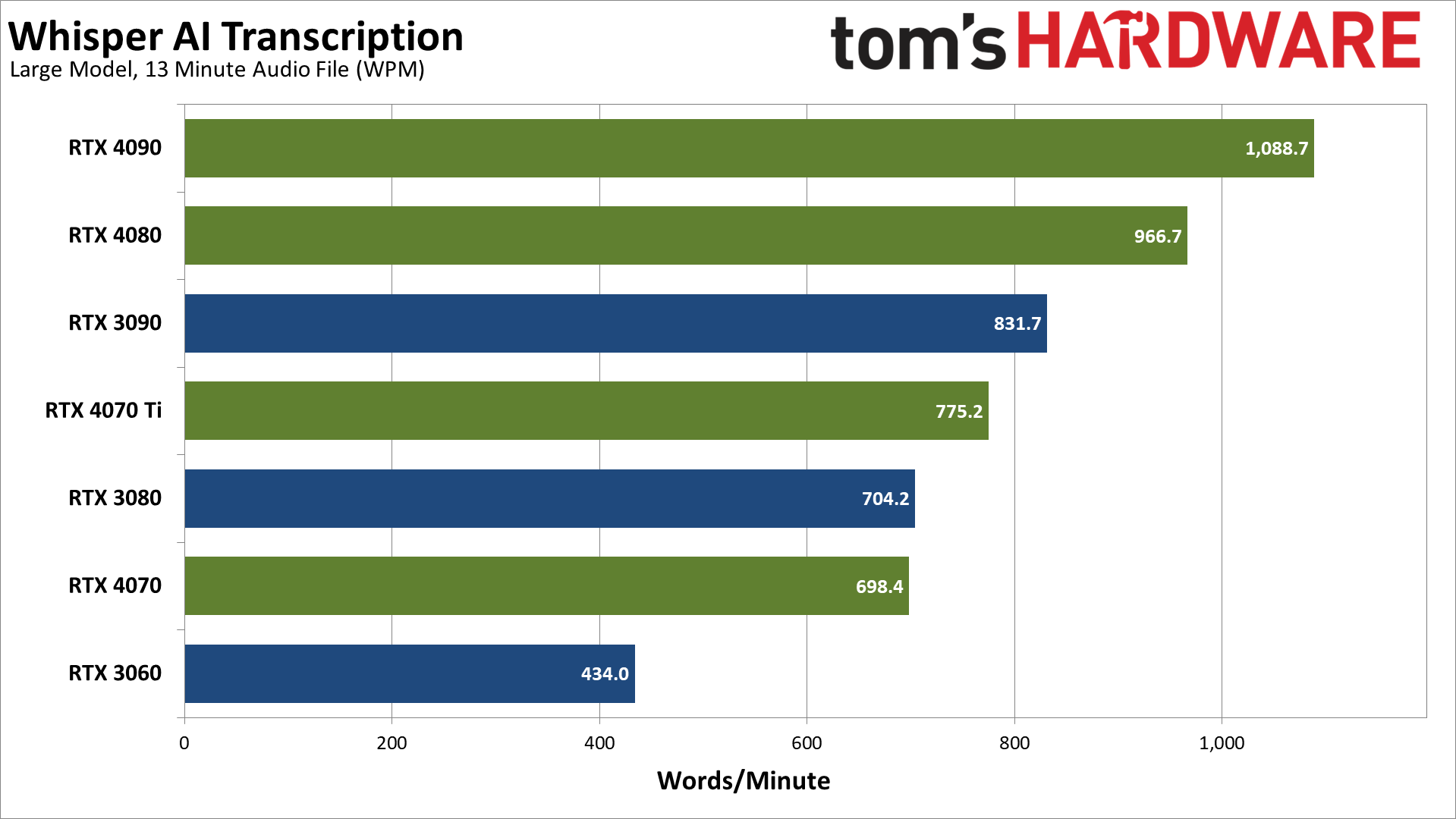
The large model increases the VRAM requirements to around 10GB with PyTorch, which means the RTX 3070 and RTX 3050 can't even try to run the transcription. Performance drops by about 40% on most of the GPUs, though the 4090 and 4080 see less of a drop due to the CPU limits.
It's pretty wild to see how much faster the Const-Me C++ version runs. Maybe it all just comes down to having FP16 calculations (which are required for DX11 certification). Not only does it run faster, but we could even run the large model with a 6GB card, while the PyTorch code needs at least a 10GB card.
Whisper PyTorch, GPU Power and Efficiency
We only collected power use while running the medium model — mostly because we didn't think to collect power data until we had already started testing. Because we're hitting CPU limits on the fastest cards, it's no surprise that the 4090 and 4080 come in well below their rated TGP (Total Graphics Power).
The 4090 needs just under 200W while the 4080 is a bit more efficient at less than 180W. Both GPUs also use more power with PyTorch than they did using WhisperDesktop, however. The RTX 3080 and 3090 even get somewhat close to their TGPs.
Converting to efficiency in words per minute per watt, the Ada Lovelace RTX 40-series cards are anywhere from 43% to 103% more efficient than the Ampere RTX 30-series GPUs. The faster GPUs of each generation tend to be slightly less efficient, except for the RTX 4080 that takes the top spot.
Again, it's clear the OpenAI GitHub source code hasn't been fully tuned for maximum performance — not even close. We can't help but wonder what performance might look like with compiled C++ code that actually uses Nvidia's tensor cores. Maybe there's a project out there that has already done that, but I wasn't able to find anything in my searching.
Whisper AI Closing Thoughts
As we've noted on numerous occasions, support for Nvidia's GPUs via CUDA tends to be the de facto standard in many AI projects these days. The most popular projects often get AMD GPU support... eventually; sometimes there are even Intel forks. For Whisper, there are currently a couple of options: ROCm and CUDA translation running under Linux, or a DirectCompute implementation that's far more compact and performant. It's almost like Python tends to not be an optimal way of coding things.
Hardware requirements can also vary quite a bit, depending on which version of Whisper you want to use. WhisperDesktop basically only needs enough VRAM to hold the model, while the PyTorch version requires about double the VRAM.
That means, like Stable Diffusion that can run even on GPUs with 4GB of memory, WhisperDesktop isn't particularly demanding on VRAM. But the PyTorch version is a lot more like other large language models (LLMs) and definitely wants more memory, sometimes a lot more. OpenAI only released a large model for Whisper (based on GPT-2) that needs about 10GB of memory, but certainly it could work to improve the accuracy and quality even more while requiring additional VRAM.
Our testing of Whisper also shows that coding and optimizations can often trump hardware. In theory, Nvidia's tensor cores should allow a GPU like the RTX 4090 to be potentially 2.7X faster than an RX 7900 XTX, based on FP16 compute potential — double that to 5.4X faster if sparsity applies. But WhisperDesktop doesn't bother with tensor cores and so we're left with FP16 GPU shader compute performance. Or maybe not even that, as in theory the double performance FP16 of RDNA3 GPUs would then put them ahead of the Ada GPUs.
If you have any suggestions on other AI workloads you'd like to see us test, or a different version of Whisper that might better take advantage of Nvidia's tensor cores and/or Intel's XMX cores, let us know in the comments. We're always looking for potentially useful and interesting tests to quantify GPU performance.
Ultimately, Whisper isn't necessarily the sort of tool that tons of people will find useful, and there are other transcription services and speech recognition applications available. However, given the price — free, assuming you have any GPU made in the past decade or so — Whisper once again illustrates the potential of AI training algorithms. It's certainly a tool we'll keep in mind for the future.







