
Nvidia CEO Jensen Huang announced here at Computex 2023 in Taipei, Taiwan that the company's Grace Hopper superchips are now in full production, and the Grace platform has now earned six supercomputer wins. These chips are a fundamental building block of one of Huang's other big Computex 2023 announcements: The company's new DGX GH200 AI supercomputing platform, built for massive generative AI workloads, is now available with 256 Grace Hopper Superchips paired together to form a supercomputing powerhouse with 144TB of shared memory for the most demanding generative AI training tasks. Nvidia already has customers like Google, Meta, and Microsoft ready to receive the leading-edge systems.
Nvidia also announced its new MGX reference architectures that will help OEMs build new AI supercomputers faster with up to 100+ systems available. Finally, the company also announced its new Spectrum-X Ethernet networking platform that is designed and optimized specifically for AI server and supercomputing clusters. Let's dive in.








Nvidia Grace Hopper Superchips Now in Production

We've covered the Grace and Grace Hopper Superchips in depth in the past. These chips are central to Nidia's new systems that it announced today. The Grace chip is Nvidia's own Arm CPU-only processor, and the Grace Hopper Superchip combines the Grace 72-core CPU, a Hopper GPU, 96GB of HBM3, and 512 GB of LPDDR5X on the same package, all weighing in at 200 billion transistors. This combination provides astounding data bandwidth between the CPU and GPU, with up to 1 TB/s of throughput between the CPU and GPU offering a tremendous advantage for certain memory-bound workloads.
With the Grace Hopper Superchips now in full production, we can expect systems to come from a bevy of Nidia's systems partners, like Asus, Gigabyte, ASRock Rack, and Pegatron. More importantly, Nvidia is rolling out its own systems based on the new chips and is issuing reference design architectures for OxMs and hyperscalers, which we’ll cover below.
Nvidia DGX GH200 Supercomputer
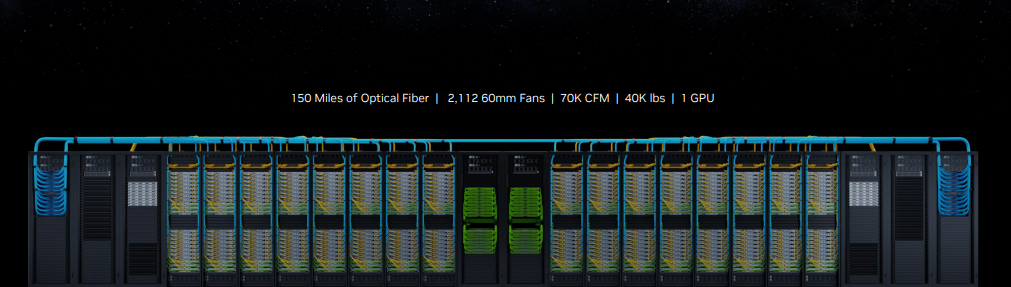

Nvidia's DGX systems are its go-to system and reference architecture for the most demanding AI and HPC workloads, but the current DGX A100 systems are limited to eight A100 GPUs working in tandem as one cohesive unit. Given the explosion of generative AI, Nvidia's customers are eager for much larger systems with much more performance, and the DGX H200 is designed to offer the ultimate in throughput for massive scalability in the largest workloads, like generative AI training, large language models, recommender systems and data analytics, by sidestepping the limitations of standard cluster connectivity options, like InfiniBand and Ethernet, with Nvidia's custom NVLink Switch silicon.
Details are still slight on the finer aspects of the new DGX GH200 AI supercomputer, but we do know that Nvidia uses a new NVLink Switch System with 36 NVLink switches to tie together 256 GH200 Grace Hopper chips and 144 TB of shared memory into one cohesive unit that looks and acts like one massive GPU. The new NVLink Switch System is based on its NVLink Switch silicon that is now in its third generation.
The DGX GH200 comes with 256 total Grace Hopper CPU+GPUs, easily outstripping Nvidia's previous largest NVLink-connected DGX arrangement with eight GPUs, and the 144TB of shared memory is 500X more than the DGX A100 systems that offer a 'mere' 320GB of shared memory between eight A100 GPUs. Additionally, expanding the DGX A100 system to clusters with more than eight GPUs requires employing InfiniBand as the interconnect between systems, which incurs performance penalties. In contrast, the DGX GH200 marks the first time Nvidia has built an entire supercomputer cluster around the NVLink Switch topology, which Nvidia says provides up to 10X the GPU-to-GPU and 7X the CPU-to-GPU bandwidth of its previous-gen system. It's also designed to provide 5X the interconnect power efficiency (likely measured as PJ/bit) than competing interconnects, and up to 128 TB/s of bisectional bandwidth.
The system has 150 miles of optical fiber and weighs 40,000 lbs, but presents itself as one single GPU. Nvidia says the 256 Grace Hopper Superchips propel the DGX GH200 to one exaflop of 'AI performance,' meaning that value is measured with smaller data types that are more relevant to AI workloads than the FP64 measurements used in HPC and supercomputing. This performance comes courtesy of 900 GB/s of GPU-to-GPU bandwidth, which is quite impressive scalability given that Grace Hopper tops out at 1 TB/s of throughput with the Grace CPU when connected directly together on the same board with the NVLink-C2C chip interconnect.
Nvidia provided projected benchmarks of the DGX GH200 with the NVLink Switch System going head-to-head with a DGX H100 cluster tied together with InfiniBand. Nvidia used varying numbers of GPUs for the above workload calculations, ranging from 32 to 256, but each system employed the same number of GPUs for each test. As you can see, the explosive gains in interconnect performance are expected to unlock anywhere from 2.2X to 6.3X more performance.
Nvidia will provide the DGX GH200 reference blueprints to its leading customers, Google, Meta, and Microsoft, before the end of 2023, and will also provide the system as a reference architecture design for cloud service providers and hyperscalers.
Nvidia is eating its own dogfood, too; the company will deploy a new Nvidia Helios supercomputer comprised of four DGX GH200 systems that it will use for its own research and development work. The four systems, which total 1,024 Grace Hopper Superchips, will be tied together with Nvidia's Quantum-2 InfiniBand 400 Gb/s networking.
Nvidia MGX Systems Reference Architectures

While DGX steps in for the highest-end systems, Nvidia’s HGX systems step in for hyperscalers. However, the new MGX systems step in as the middle point between these two systems, and DGX and HGX will continue to co-exist with the new MGX systems.
Nvidia’s OxM partners face new challenges with AI-centric server designs, thus slowing design and deployment. Nvidia’s new MGX reference architectures are designed to speed that process with 100+ reference designs. The MGX systems comprise modular designs that span the gamut of Nvidia’s portfolio of CPUs and GPUs, DPUs, and networking systems, but also include designs based on the common x86 and Arm-based processors found in today’s servers. Nvidia also provides options for both air- and liquid-cooled designs, thus providing OxMs with different design points for a wide range of applications.







Naturally, Nvidia points out that the lead systems from QCT and Supermicro will be powered by its Grace and Grace Hopper Superchips, but we expect that x86 flavors will probably have a wider array of available systems over time. Asus, Gigabyte, ASRock Rack and Pegatron will all use MGX reference architectures for systems that will come to market later this year into early next year.
The MGX reference designs could be the sleeper announcement of Nvidia’s Computex press blast – these will be the systems that mainstream data centers and enterprises will eventually deploy to infuse AI-centric architectures into their deployments, and will ship in far greater numbers than the somewhat exotic and more costly DGX systems – these are the volume movers. Nvidia is still finalizing the spec, which will be public, and will release a whitepaper soon.
Nvidia Spectrum-X Networking Platform
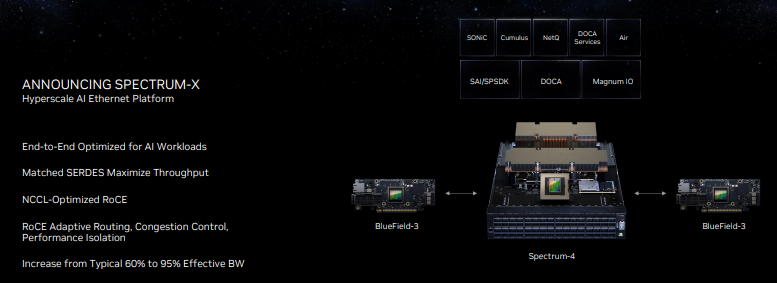

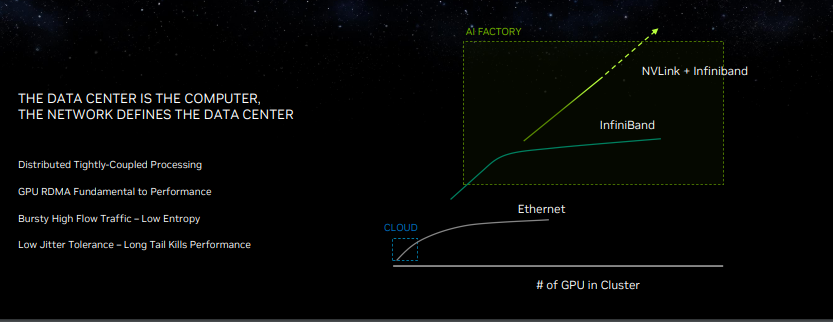
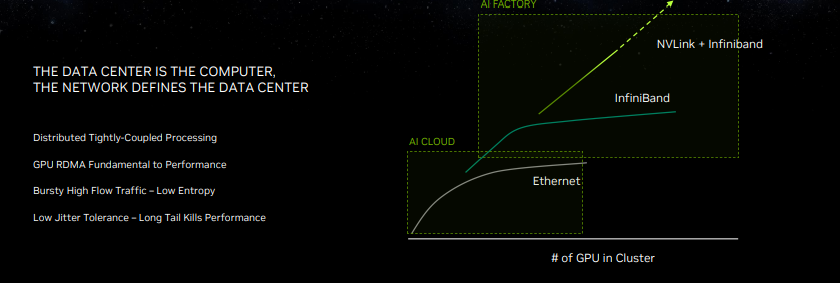
Nvidia’s purchase of Mellanox has turned out to be a pivotal move for the company, as it can now optimize and tune networking componentry and software for its AI-centric needs. The new Spectrum-X networking platform is perhaps the perfect example of those capabilities, as Nvidia touts it as the ‘world’s first high-performance Ethernet for AI’ networking platform.





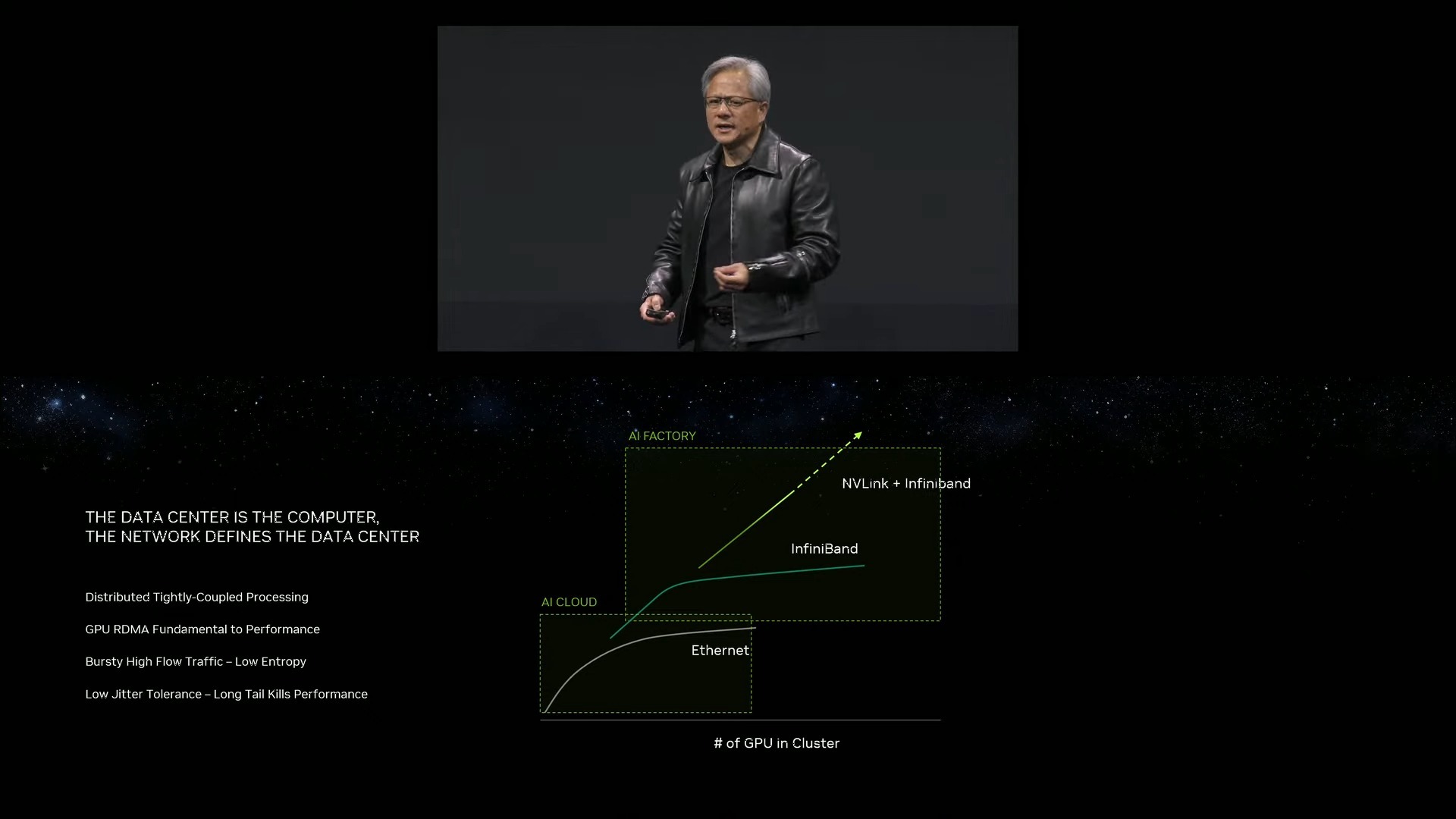


One of the key points here is that Nvidia is pivoting to Ethernet as an interconnect option for high-performance AI platforms, as opposed to the InfiniBand connections often found in high-performance systems. The Spectrum-X design employs Nvidia’s 51 Tb/s Spectrum-4 400 GbE Ethernet switches and the Nvidia Bluefield-3 DPUs paired with software and SDKs that allow developers to tune systems for the unique needs of AI workloads. In contrast to other Ethernet based systems, Nvidia says Spectrum-X is lossless, thus providing superior QoS and latency. It also has new adaptive routing tech, which is particularly helpful in multi-tenancy environments.
The Spectrum-X networking platform is a foundational aspect of Nvidia’s portfolio, as it brings high-performance AI cluster capabilities to Ethernet-based networking, offering new options for wider deployments of AI into hyperscale infrastructure. The Spectrum-X platform is also fully interoperable with existing Ethernet-based stacks and offers impressive scalability with up to 256 200 Gb/s ports on a single switch, or 16,000 ports in a two-tier leaf-spine topology.
The Nvidia Spectrum-X platform and its associated components, including 400G LinkX optics, are available now.
Nvidia Grace and Grace Hopper Superchip Supercomputing Wins
Nvidia's first Arm CPUs (Grace) have already been in production and made an impact with three recent supercomputer wins, including the newly announced Taiwania 4 which will be built by computing vendor ASUS for the Taiwan National Center for High-Performance Computing. This system will feature 44 Grace CPU nodes, and Nvidia claims it will rank among the most energy-efficient supercomputers in Asia when deployed. The supercomputer will be used to model climate change issues.
Nvidia also shared details of its new Taipei 1 supercomputer that will be based in Taiwan. This system will have 64 DGX H100 AI supercomputers and 64 Nvidia OVX systems tied together with the company's networking kit. This system will be used to further unspecified local R&D workloads when it is finished later this year.







