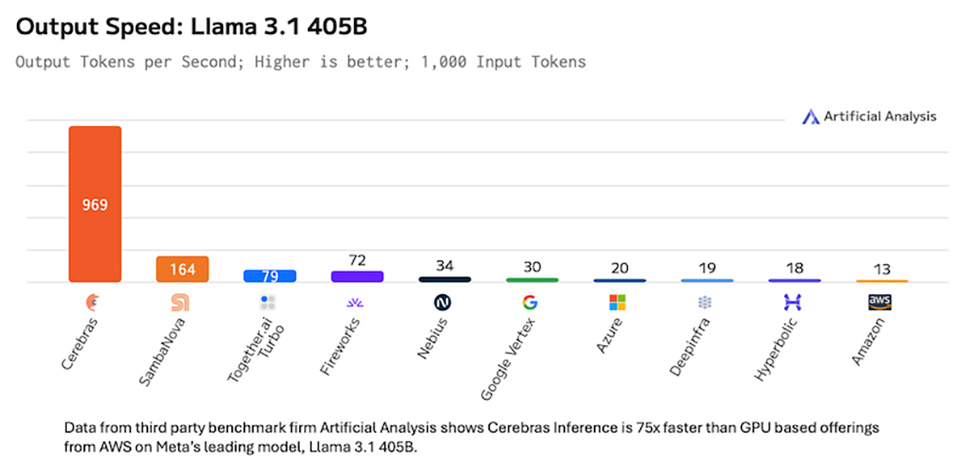
- Cerebras hits 969 tokens/second on Llama 3.1 405B, 75x faster than AWS
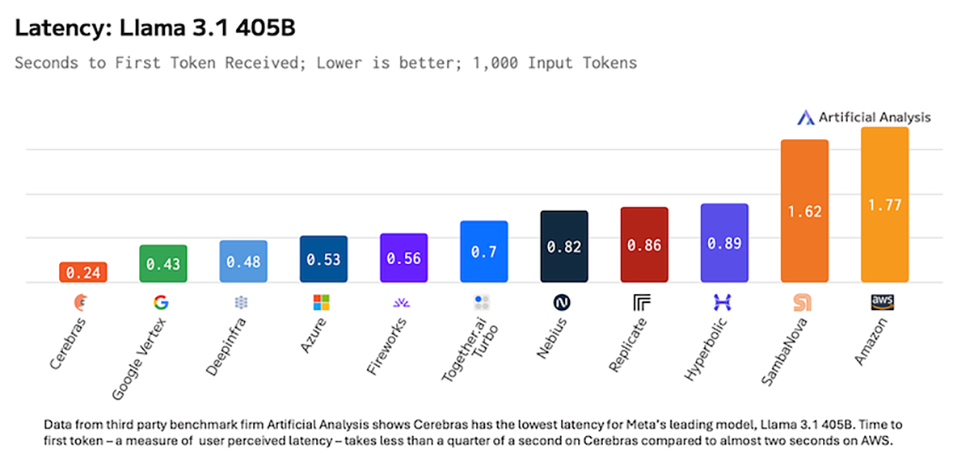
- Claims industry-low 240ms latency, twice as fast as Google Vertex
- Cerebras Inference runs on the CS-3 with the WSE-3 AI processor
Cerebras Systems says it has set a new benchmark in AI performance with Meta’s Llama 3.1 405B model, achieving an unprecedented generation speed of 969 tokens per second.
Third-party benchmark firm Artificial Analysis has claimed this performance is up to 75 times faster than GPU-based offerings from major hyperscalers. It was nearly six times faster than SambaNova at 164 tokens per second, more than 14 times faster than Google Vertex at 30 tokens per second, and far surpassing Azure at just 20 tokens per second and AWS at 13 tokens per second.
Additionally, the system demonstrated the fastest time to first token in the world, clocking in at just 240 milliseconds - nearly twice as fast as Google Vertex at 430 milliseconds and far ahead of AWS at 1,770 milliseconds.
Extending its lead
“Cerebras holds the world record in Llama 3.1 8B and 70B performance, and with this announcement, we’re extending our lead to Llama 3.1 405B - delivering 969 tokens per second," noted Andrew Feldman, co-founder and CEO of Cerebras.
"By running the largest models at instant speed, Cerebras enables real-time responses from the world’s leading open frontier model. This opens up powerful new use cases, including reasoning and multi-agent collaboration, across the AI landscape.”
The Cerebras Inference system, powered by the CS-3 supercomputer and its Wafer Scale Engine 3 (WSE-3), supports full 128K context length at 16-bit precision. The WSE-3, known as the “fastest AI chip in the world,” features 44GB on-chip SRAM, four trillion transistors, and 900,000 AI-optimized cores. It delivers a peak AI performance of 125 petaflops and boasts 7,000 times the memory bandwidth of the Nvidia H100.
Meta’s GenAI VP Ahmad Al-Dahle also praised Cerebras' latest results, saying, “Scaling inference is critical for accelerating AI and open source innovation. Thanks to the incredible work of the Cerebras team, Llama 3.1 405B is now the world’s fastest frontier model. Through the power of Llama and our open approach, super-fast and affordable inference is now in reach for more developers than ever before.”
Customer trials for the system are ongoing, with general availability slated for Q1 2025. Pricing begins at $6 per million input tokens and $12 per million output tokens.