
Speech and voice is clearly the next big battleground for generative AI and a number of companies are working hard to produce models that can understand and replicate natural voice patterns. And while the likes of ChatGPT Voice could change storytelling forever, Microsoft claims it's hit the apex of speech generation: human parity.
In fact, the company's researchers say their VALL-E 2 text-to-speech (TTS) generator is so advanced, it would be irresponsible and dangerous to release publicly. According to a research paper (spotted by our sister title, LiveScience) the generator needs just a few seconds of audio to reproduce a voice that's indistinguishable from a human.
To put that in perspective, the scientists at Microsoft believe the speech generated by VALL-E 2 matches or exceeds the quality of a human voice when compared to the audio samples from speech libraries LibriSpeech and VCTK.
"VALL-E 2 is the latest advancement in neural codec language models that marks a milestone in zero-shot text-to-speech synthesis (TTS), achieving human parity for the first time," the researchers wrote. "Moreover, VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases."
While the first generation model sounds stilted, there's no denying VALL-E 2 does an exceptional job of copying the resonance and articulation of the speaker.
Although the researchers aren't releasing the model publicly (more on that later), they have made several audio samples available to listen to in a blog post about the project. You can hear a speaker prompt sourced from LibriSpeech and then the resulting generation of an entirely new (complex) sentence from both the VALL-E and VALL-E 2 generators.
And while the first generation model sounds stilted, there's no denying VALL-E 2 does an exceptional job of copying the resonance and articulation of the speaker.
How does it work?
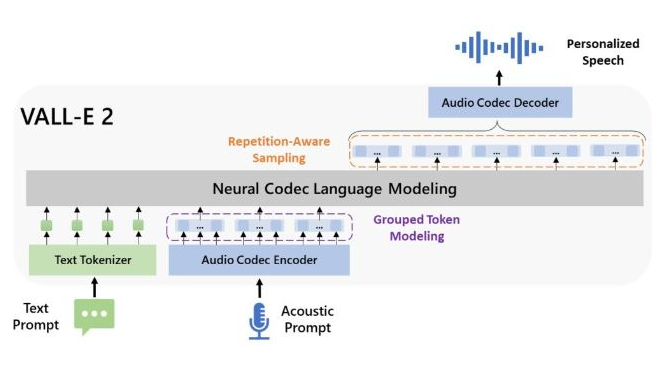
Microsoft's VALL-E 2 TTS generator uses two specific features to achieve its impressive result: "Repetition Aware Sampling" and "Grouped Code Modeling."
The first is designed to make the output sound more fluid by addressing performance issues around repetitions of small parts of words or phrases (known as tokens) that may trip up an AI — think of an alliteration-heavy sentence, for example.
The second feature also improves efficiency but does do by reducing the number of individual tokens the model processes in a single input sequence.
"VALL-E 2 surpasses previous zero-shot TTS systems in speech robustness, naturalness, and speaker similarity," the researchers wrote in the blog post. "VALL-E 2 can generate accurate, natural speech in the exact voice of the original speaker, comparable to human performance."
Too dangerous?

Although Microsoft maintains there are uses for an AI speech generator capable of this level of output, such as producing speech for individuals with aphasia or people with amyotrophic lateral sclerosis, the company is keeping it research-only at present.
"Currently, we have no plans to incorporate VALL-E 2 into a product or expand access to the public," the scientists wrote. This is in part due to the potential for misuse that could be encountered once the world at large was able to use it. In an ethics statement at the end of the post, the researchers wrote their creation, "may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker."
This isn't unique to Microsoft. OpenAI, creators of ChatGPT, have also placed restrictions on some of its voice tech and has created a deepfake detector as a means of helping users identify when images are created using AI. Whether or not VALL-E 2 (or its successor) stays closed off remains to be seen. The AI race will intensify over the coming months and years and companies and scientists will no doubt feel the pressure to push the envelope.







