
As we start to become more reliant on AI, it's only a matter of time until we'll need to have access to the latest chatbots through our phones.
Research scientists at Meta Reality Labs say that with an increasing reliance on large language models (LLMs) people may soon be spending more than an hour every day either in direct conversations with chatbots or having LLM processes run in the background powering features such as recommendations.
While all we usually see is ChatGPT quickly replying to our questions, the energy consumption and carbon dioxide emissions required to make these replies happen “would present staggering environmental challenges” if AI continues in its current trajectory the scientists said in a preprint paper released February 22.
Make it smaller
One solution is to deploy these large language models directly on our phones – solving portability and computational cost issues simultaneously.
Sure, you could technically run models such as Meta’s Llama 2 directly on your iPhone today, but the scientists calculated the battery would cope with less than two hours of conversation. That’s not realistic for consumers. It would also lead to long wait times for a response due to memory limitations.
What’s needed is a compact LLM model designed for phones. Meta’s team think they have found a solution in what they’re calling MobileLLM which they claim actually has a fractional boost in accuracy over other similar state-of-the-art models.
Working with a mobile LLM
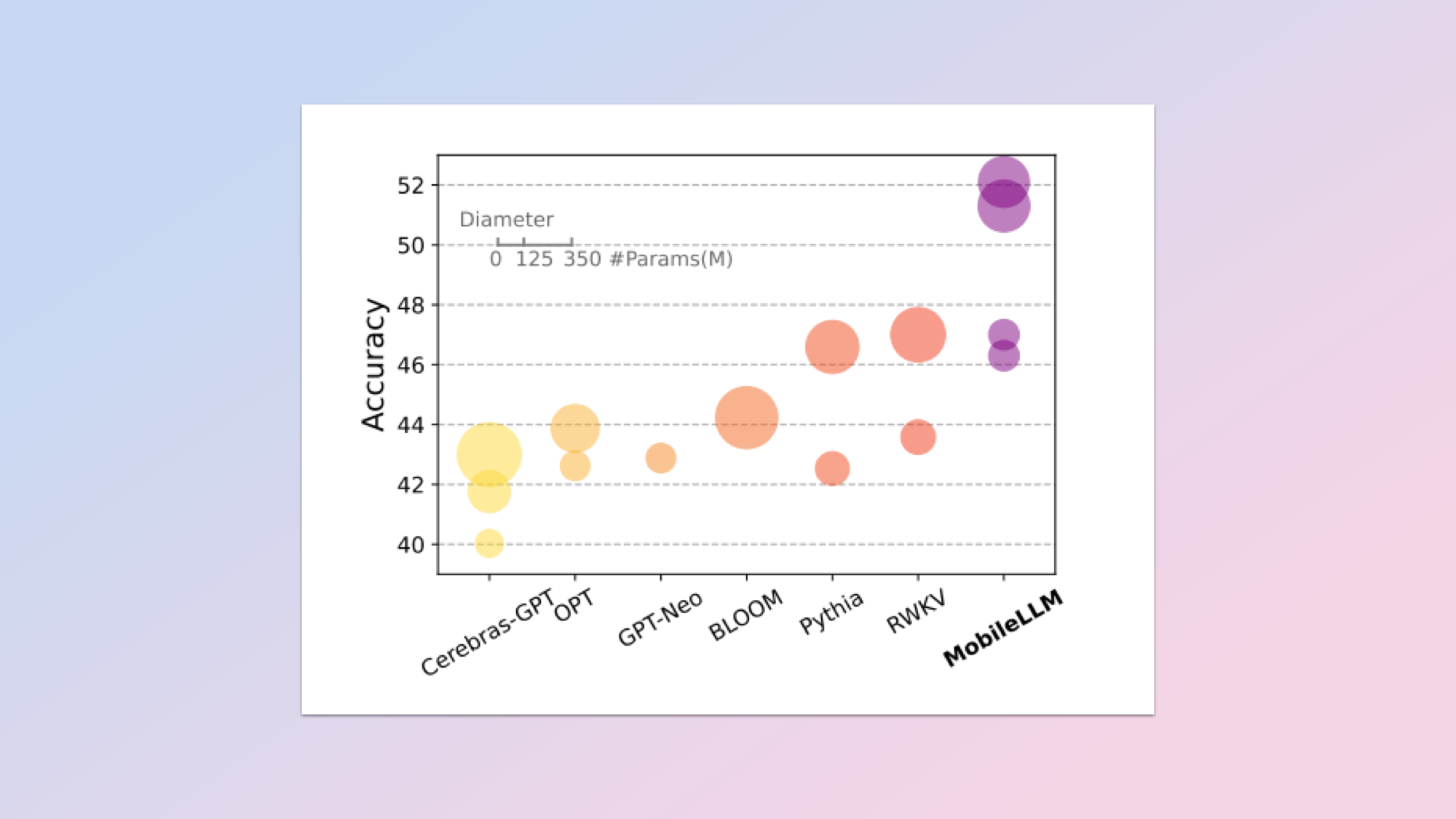
When looking under the hood of an LLM, one main characteristic that can be observed is the model size. This is calculated in the number of parameters.
The more parameters it has, the more complex it is, allowing for more data to be processed. GPT-4 from OpenAI, regarded as the most powerful model on the scene, exceeds one trillion parameters. But as mentioned earlier, such a heavy model requires more energy and compute power to work.
Meta’s researcher think they can create top-quality LLMs with less than a billion parameters (that’s still 174 billion parameters less than in GPT-3).
To make that happen they found that they could enhance overall performance by prioritizing depth features such as intellectual skills and advanced reasoning over width, or the ability to perform across a wide range of tasks.
In cases where data storage is more limited, as is the case in smartphones, they also saw that using grouped query attention also helps. This is when a model can focus on different parts of a prompt grouped together, allowing parallel processing. Again, it also uses less memory and energy to work.
Chat and API calling to the test
To validate the effectiveness of sub-billion scale models for on-device applications, they assessed their performance in two crucial on-device tasks: Chat and API calling.
To evaluate chat functionality they used two leading benchmarks, namely AlpacaEval and MT-Bench and found that their MobileLLM models outperformed other state-of-the-art sub-billion scale models.
API calling meanwhile is the process of having one piece of software communicate with another to perform tasks outside of its own programming. So for instance you asking for an alarm to wake you up in the morning sets it in the clock app of your phone along with a text confirmation like: Sure! Your alarm is set to 7:30 AM.
Finding a balance
It’s all about finding the right balance at the end of the day. Having an omniscient phone sounds great, but if it can only last two hours before you need to start looking for a power outlet that starts to sound less appealing.
Apple is also actively working on this problem as a future LLM-powered Siri would likely require significant on-device processing due to Apple's security requirements.
As companies continue to add AI features to their phones, they may very find some answers to their questions from Meta’s research about how and where to reach the right compromises for their LLMs.







