Cloud and IT go hand in hand, so as IT leaders, you likely need a comprehensive, clear insight into the technologies that feed both the enterprise and the cloud. Of paramount importance to IT leaders and cloud architects is keeping your technology assets secure, well-governed and cost effective. This is a far cry from where IT was a decade or more ago, whereby IT was pictured more as support for the back office and keeping “the network” functional—as well as supporting the users and workplace.
IT leaders need comprehensive, clear insights into their technology to fuel this evasive and evolving data-driven, decision-making processes, which lead to the best of results. The cloud, while convenient and less involved (compared to an enterprise-size data center) is not without its concerns. This is not to be “negative” about the cloud. Quite the contrary, knowing pitfalls of the cloud can only make your implementation(s) better and less risky.
By looking at known issues, we hope to broaden perspective and set the tone for understanding how, why or why not “in the cloud.”
Lifecycle
Most products sold to users have some concept of how long it will last. This “lifecyle” is no different for automobiles, appliances and certainly electronics. Like hardware, software also has its own version of how long it will last—sometimes based on the hardware it lives on and sometimes just how long the original equipment manufacturer (OEM) wishes to support it or feels it is worthy of maintaining due to technology changes (usually advancements) or their cost of keeping it alive.
In IT (and cloud) , there is also a software lifecycle. In this case, the software asset lifecycle is about having your IT resources accounted for, cost-effective and properly employed. Vulnerabilities of the products lead the list of concerns about IT assets according to Flexera’s 2021 “State of IT Visibility Report.” This issue is a chief concern of the enterprise information management and staff. The same issues can be and are extended into cloud practices and, like the “ground-based” enterprise, must be carefully understood, watched and protected. The sidebar provides simple definitions as they apply to software systems and hardware components.

In considering cloud, many look at using a combination of ground-based (on-prem) services and cloud services. This is generally referred to as a “hybrid” cloud service and some feel this is not only important, but it may also be essential to its operation. In this model there is a dual role—that is, here the enterprise must manage its own services (on-prem) and in turn manage its cloud services as well.
Is a Hybrid Cloud the Right Answer?
According to Morpheus’ “Gartner Market Guide for Cloud Management Tooling,” “The requirement to support hybrid and/or multicloud deployments is stressing current enterprise operational processes and tooling that had been designed for their on-premises environment. The main use cases continue to be around cloud governance and resource management as enterprises try to avoid overspending or falling prey to security breaches.”
By definition, a hybrid cloud is a mixed computing environment where applications are run using a combination of computing, storage and services in different environments—public clouds and private clouds, including on-premises data centers or “edge” locations.
On a broader perspective, hybrid cloud architectures are widespread primarily because almost no one today relies entirely on a single public cloud. Figs. 1 and 2 show the values and benefits of employing a hybrid cloud to your solutions.
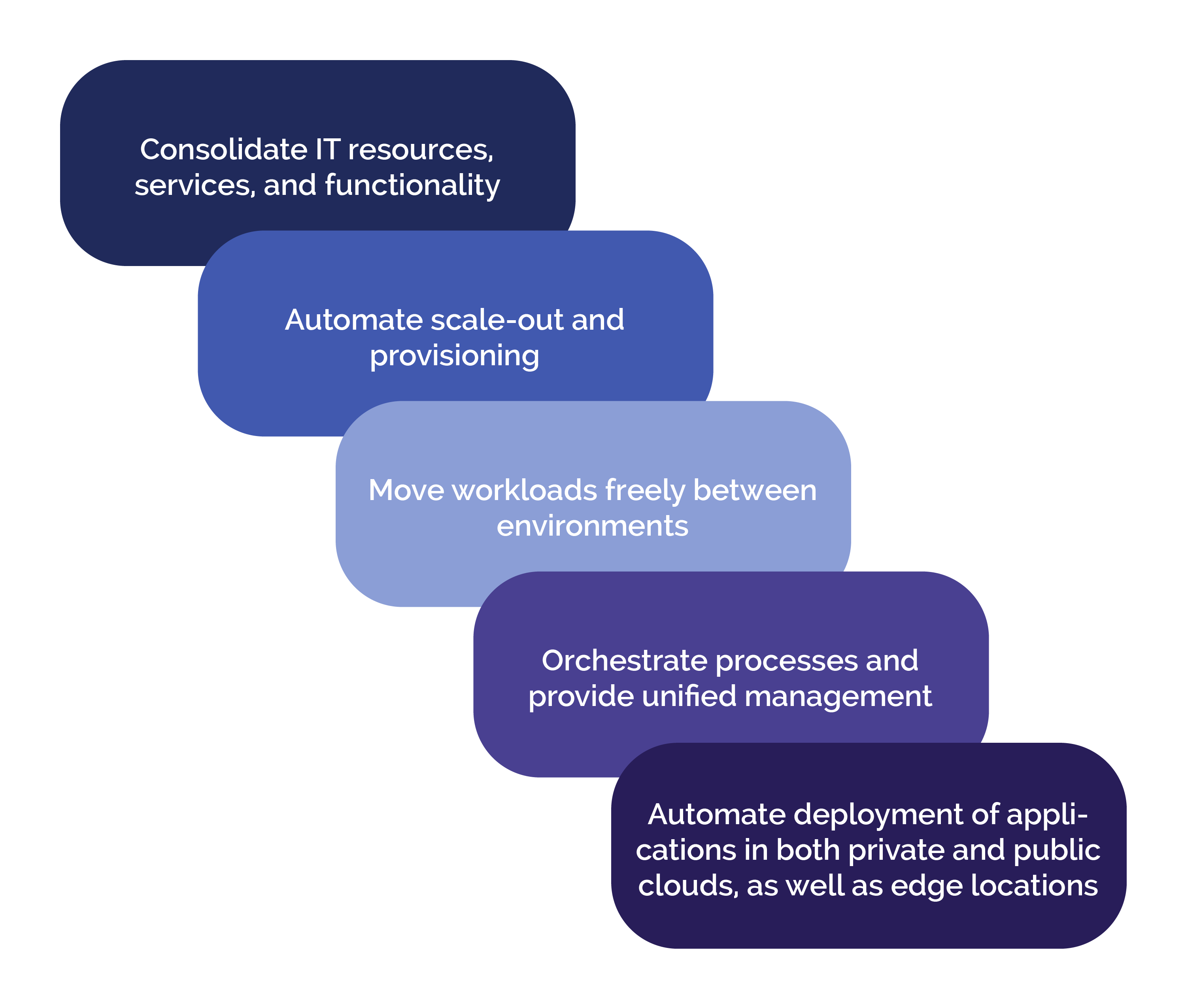

The value is that in hybrid cloud solutions you need to migrate and manage workloads between various cloud (and ground) environments. In turn, this allows users to create more versatile setups based on specific business needs. Many organizations choose to adopt hybrid cloud platforms to reduce costs, minimize risk and extend their existing capabilities to support digital transformation efforts.
A hybrid cloud approach is one of the most common infrastructure architectures of modern computing applications for IT, media, healthcare, and the list goes on. Today, most cloud migrations often lead to hybrid cloud implementations as organizations often have to transition applications and data slowly and systematically. Hybrid cloud environments allow you to continue using on-premises services while taking advantage of the flexible options for storing and accessing data and applications offered by public cloud providers, such as Google Cloud.
The Good and the Bad
On the other side of the coin, there are many reasons why there are plenty of workloads that will never go to public cloud—some of which include: regulatory response, life/safety reasons, subscription vs. permanent cost models, less control over your data security, and of course, you must have good Internet.
The “if it’s not broke don’t fix it,” and the “one throat to choke (your own),” along with long-term costs of cloud computing being higher, all stack up against the “all in the cloud” model. Users also say some applications actually run better on a local server along with not knowing “where” your data really is (risk of regulations that could impact data retention or recovery, and how much does it take of your time plus the inability to control reliability.
Another not-so-pleasant concern is that every action leaves a trail (i.e., Where’s your privacy?). Many of us grew up thinking that almost everything online was anonymous. Wrong. Connecting to the web generates an IP address. Every website we visit can see that IP address, and others can “see” that information, everything from what operating system we use to the size of our screen resolution.
Nothing you do is private any longer, especially when your interaction requires or expects one to “create an account.” The main point in creating an account is to retain certain data in order to display it again later. (Privacy is lost, even if the website “says” differently. If it weren’t important, why does that site need it?)
Everyone Has a Data Profile
Every detail about us can, and often is, regularly bought and sold; cookies track us routinely. Even if you don’t accept the cookies, there are means to track and trace you. Artificial intelligence now “fills in the gaps” using other resources, such as Facebook, one of the largest repositories of personal information on the planet.
This issue isn’t limited to services with public data (as in Facebook and Twitter/X). Amazon, Google and Dropbox each store different but very intimate details about each of us. Personally Identifiable Information (“PII”) is valuable to you, to businesses and to hackers. Personable data generates a “profile” that now positions you into “classes” or groupings, which now link to other connections and end up being “mined” by organizations that profit from knowing what they know and, at times, exploiting that information for less than personal reasons.
And it’s not just cybercriminals who want your data; countless services and governmental agencies want and collect your personal details too.
HR Concerns
So, think further about your own organization or enterprise data, much of which may indeed include “your” personal data. For good reasons, HR departments take worthy concerns over their employees’ personal information and that you, the employee, trust that data to your employer.
The same might go for corporate records, contracts and such. Hence the interest and concern over security whereby they may employ technologies like blockchain to protect transactions, contracts and other confidential information.
Types of PPI
Direct identifiers, also called “sensitive PII,” are data sets that can be used to pinpoint you and only you. Quasi-identifiers, also called “non-sensitive,” are those details that can be combined with other quasi-identifiers to “label” you—classify or group you for geographic, domestic or other reasons. Quasi-identifier designations are often used for statistical analysis placing you into group(s) that describe which “you belong to.”
Direct identifiers, as mentioned, are about you and only you. Nothing you share with another person is a direct identifier—that data such as your full name, medical history, credit card details, personal identifiers such as social security or insurance numbers, or your passport number.
Europe took a hard stand less than a decade ago with its General Data Protection Regulation (GDRP), a European law enacted in about mid-2018). The GDPR concept aimed to protect you (the user) and provided a legal means to have to prove that any collector of said data had actually scrubbed and/or expunged your data from their files, should you request such action.
Initially, the 1995 EU Data Protection Directive set goals and requirements, which the EU member states were free to interpret its general goals and requirements as they see fit when complying with their national (EU) laws. Essentially, this says that organizations must have a lawful reason for collecting personal data; the amount of personal data collected must be limited to the minimum necessary to complete the lawful purpose; and that data must be deleted once the lawful purpose has been completed.
The U.S. (country-wide) has been struggling to develop a similar protection, but has essentially gotten no-where; yet California has implemented similar policies.
Where is my Data, Really?
The depth of these kinds of actions apply not only to local servers and services, but extend into the cloud, which leads to an interesting caveat. What happens when the data actually resides in a cloud that is in a non-EU country?
Hence, you can see the concerns for using “the cloud” when you don’t know where the data is or under which jurisdiction that data might be controlled at any given moment. Furthermore, these concerns become more complicated as the cloud providers expand and the resiliency models (data duplication and distribution) grow for faster, more improved services.
So, know your solution set thoroughly before jumping on the “all in the cloud” bandwagon. Keep informed or use a knowledgeable entity to help support and maintain your investments.