
Artificial intelligence models require as much useful data as possible to perform but some of the biggest AI developers are relying partly on transcribed YouTube videos without permission from the creators in violation of YouTube's own rules, as discovered in an investigation by Proof News and Wired.
The two outlets revealed that Apple, Nvidia, Anthropic, and other major AI firms have trained their models with a dataset called YouTube Subtitles incorporating transcripts from nearly 175,000 videos across 48,000 channels, all without the video creators knowing.
The YouTube Subtitles dataset comprises the text of video subtitles, often with translations into multiple languages. The dataset was built by EleutherAI, which described the dataset's goal as lowering barriers to AI development for those outside big tech companies. It's only one component of the much larger EleutherAI dataset called the Pile. Along with the YouTube transcripts, the Pile has Wikipedia articles, speeches from the European Parliament, and, according to the report, even emails from Enron.
However, the Pile has a lot of fans among the major tech companies. For instance, Apple employed the Pile to train its OpenELM AI model, while the Salesforce AI model released two years ago trained with the Pile and has since been downloaded more than 86,000 times.
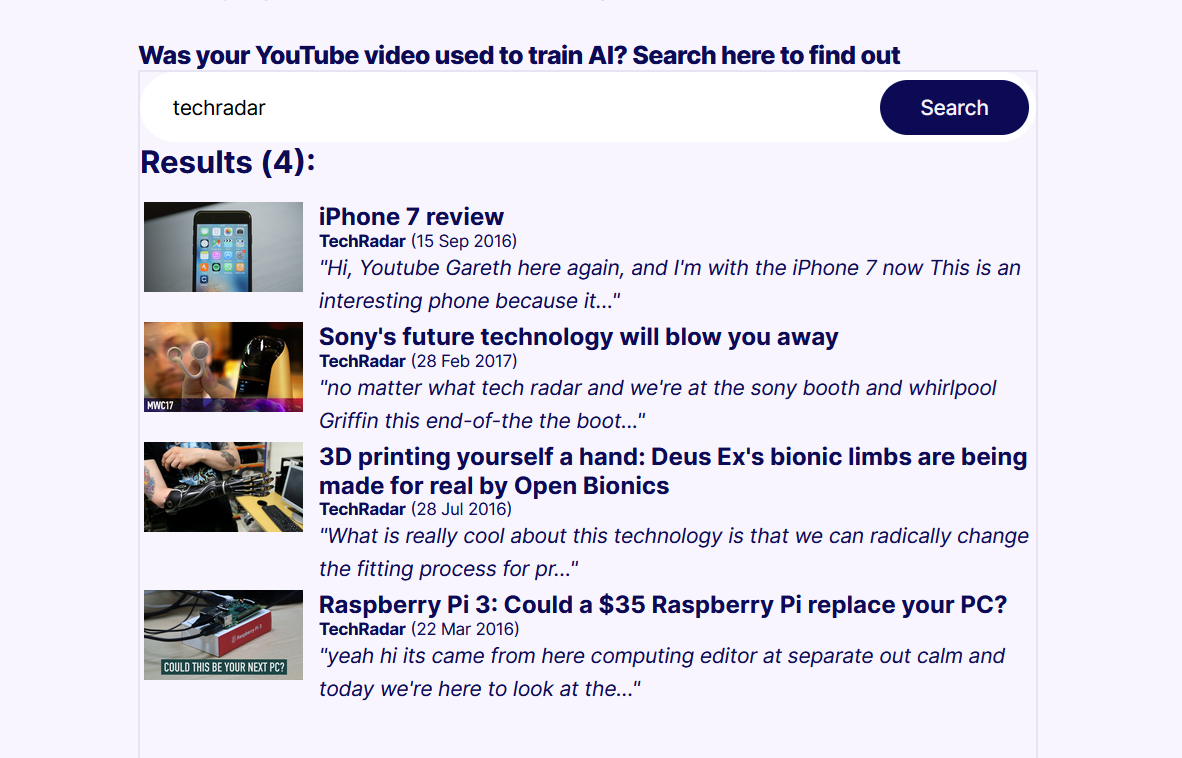
The YouTube Subtitles dataset encompasses a range of popular channels across news, education, and entertainment. That includes content from major YouTube stars like MrBeast and Marques Brownlee. All of them have had their videos used to train AI models. Proof News set up a search tool that will search through the collection to see if any particular video or channel is in the mix. There are even a few TechRadar videos in the collection, as seen below.
Secret Sharing
The YouTube Subtitles dataset seems to contradict YouTube’s terms of service, which explicitly fobird automated scraping of its videos and associated data. That’s exactly what the dataset relied on, however, with a script downloading subtitles through YouTube’s API. The investigation reported that the automated download culled the videos with nearly 500 search terms.
The discovery provoked a lot of surprise and anger from the YouTube creators Proof and Wired interviewed. The concerns about the unauthorized use of content are valid, and some of the creators were upset at the idea their work would be used without payment or permission in AI models. That’s especially true for those who found out the dataset includes transcripts of deleted videos, and in one case, the data comes from a creator who has since removed their entire online presence.
The report didn’t have any comment from EleutherAI. It did point out that the organization describes its mission as democratizing access to AI technologies by releasing trained models. That may conflict with the interests of content creators and platforms, if this dataset is anything to go by. Legal and regulatory battles over AI were already complex. This kind of revelation will likely make the ethical and legal landscape of AI development more treacherous. It’s easy to suggest a balance between innovation and ethical responsibility for AI, but producing it will be a lot harder.







