Intel has shared a slew of new benchmarks of its fourth-gen Xeon Scalable Sapphire Rapids CPUs going head-to-head with AMD's fourth-gen EPYC Genoa processors, claiming up to 7 times more performance in AI workloads when comparing two 32-core chips. Intel also touts higher performance under certain conditions, like when Sapphire Rapids' in-built accelerators are brought into play, in a spate of standard general-purpose workloads. Intel's 56-core Xeon Max, the first x86 data center CPU with HBM memory, also takes on AMD's 96-core flagship in several HPC workloads, matching or exceeding AMD's bulkier chip.
Intel's performance comparisons come well after the company's launch of its Sapphire Rapids Xeons back in January of this year, but the company says its benchmark comparisons were delayed due to difficulties procuring AMD's competing EPYC Genoa chips, which launched in November of last year. The benchmarks come a day before AMD's AI and Data Center event that we're flying out to cover, so we'll attempt to get AMD's feedback about Intel's benchmarks while we're at the event.
With a few shipping OEM systems powered by AMD's Genoa in hand, Intel has conducted a wide range of benchmarks in multiple types of workloads spanning AI, HPC, and general-purpose workloads, to present its view of the competitive landscape. However, as with all vendor-provided benchmarks, these should be approached with caution. Intel claims it enabled all rational optimizations for both its and AMD's silicon for these tests, but be aware that the comparisons can be a bit lopsided, which we'll call out where we see it. The price of the chips used for comparison are also lopsided, too. We've included Intel's full test notes for the tested configurations in the relevant image albums below. With that, let's take a closer look at Intel's results.
AI Workloads: Intel Sapphire Rapids Xeon vs AMD EPYC Genoa
For nearly every large organization, the question is no longer "if" or "when" they should deploy AI-driven applications into their deployments — the question is where and how. Yes, AI training remains the land of GPUs and various flavors of custom silicon, and we can expect Large Language Models (LLMs) to continue to rely upon those types of accelerators for the foreseeable future, but the majority of AI inference workloads still tend to run on CPUs. Given the quickening pace of AI infusion in the data center, the CPUs' performance in various types of inference will only become more important in the years to come.
Intel has had its eyes on accelerating AI workloads since the debut of its DL (Deep Learning) Boost suite with its second-gen Cascade Lake Xeon Scalable chips in 2019, which it claimed made them the first CPUs specifically optimized for AI workloads. Those chips came with support for new VNNI (Vector Neural Network Instructions) that optimized instructions for the smaller data types prized in AI applications. One of Intel's bedrock principles behind its AI strategy has been to use AVX-512 to vastly improve Xeon's performance and power efficiency in AI workloads by using VNNI and BF16. Intel's focus on AI acceleration features, including software optimizations, has expanded over the years to now include purpose-built AI acceleration engines on its Sapphire Rapids chips — if you're willing to pay the extra fee.
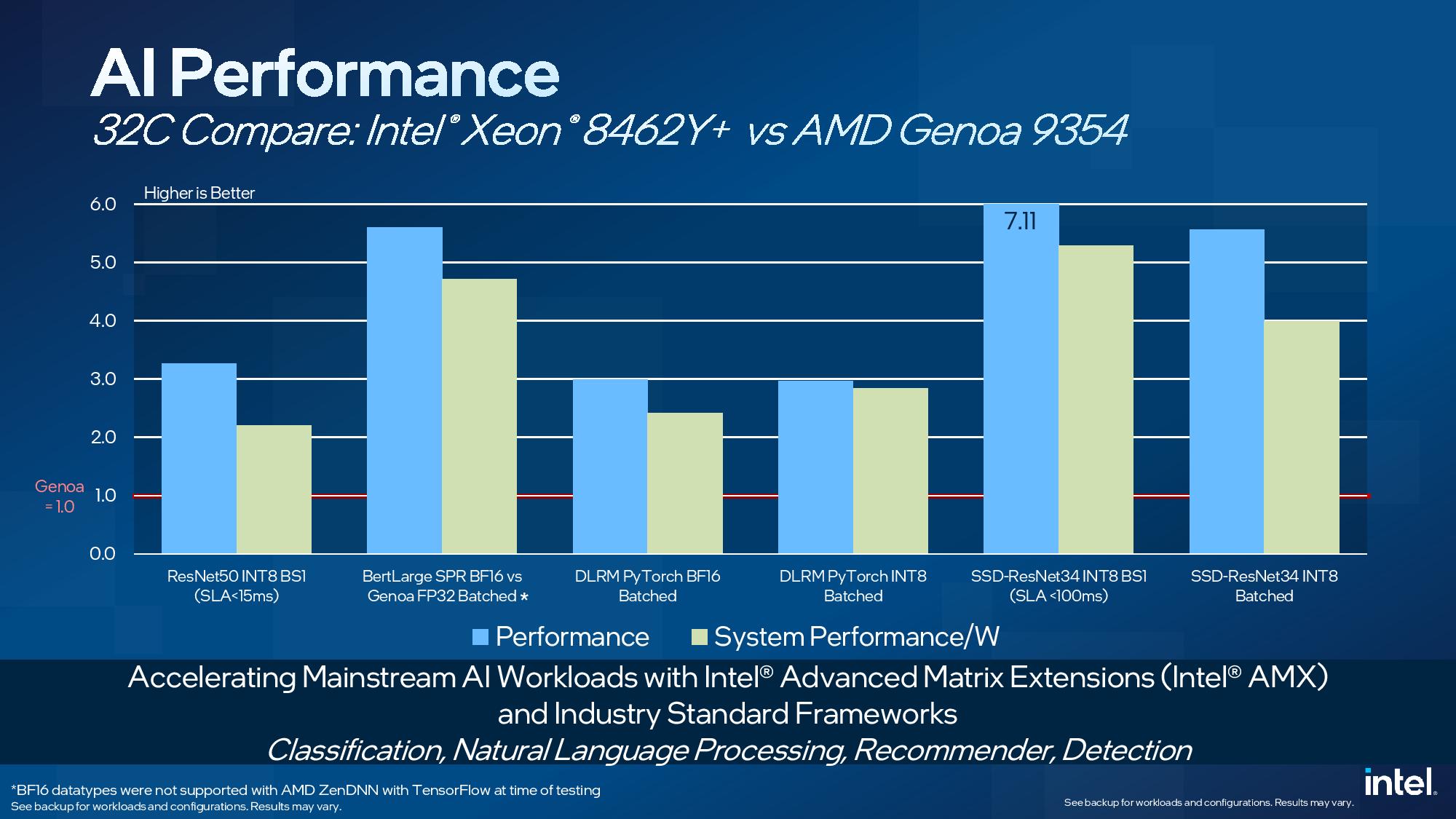
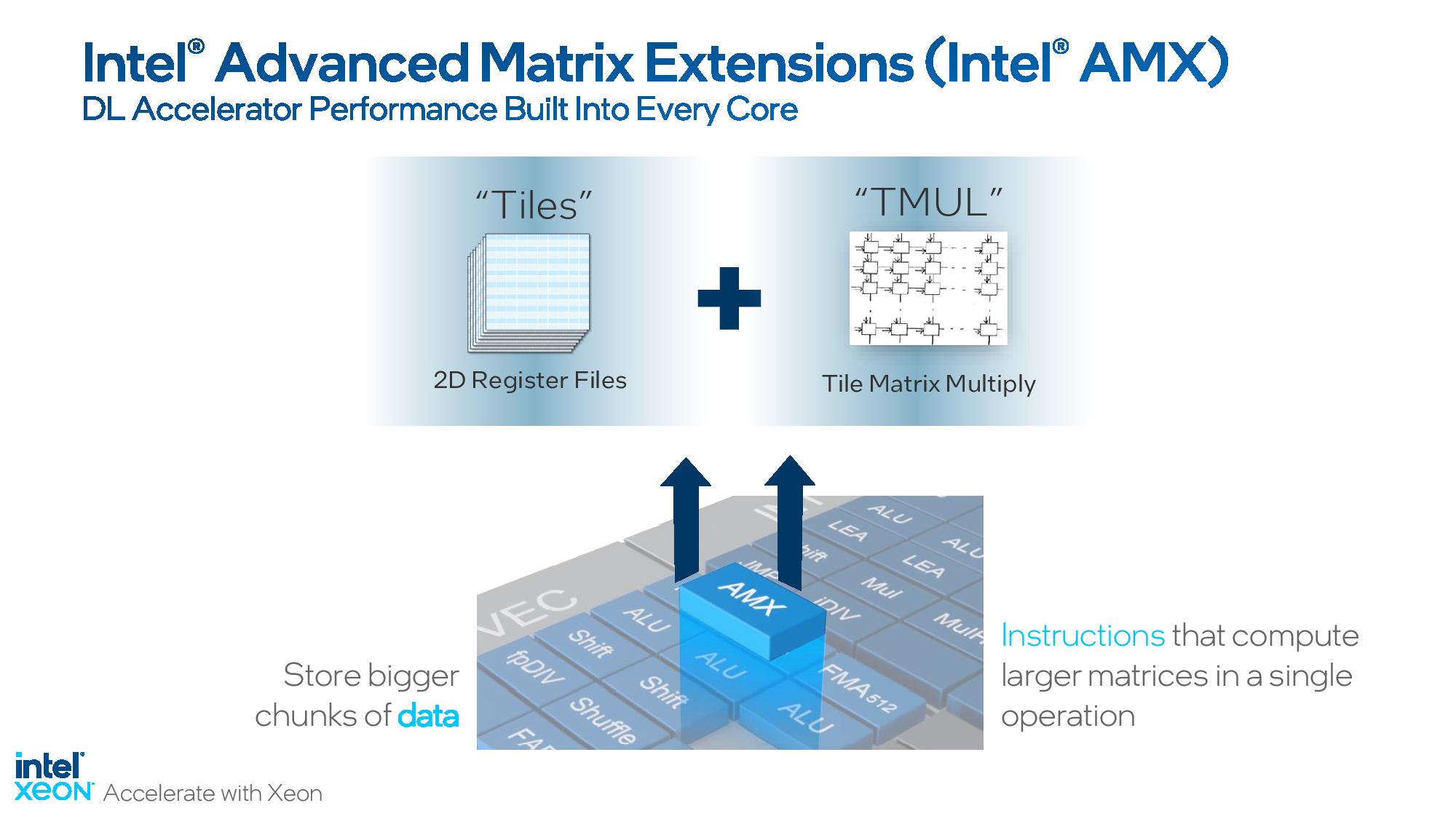
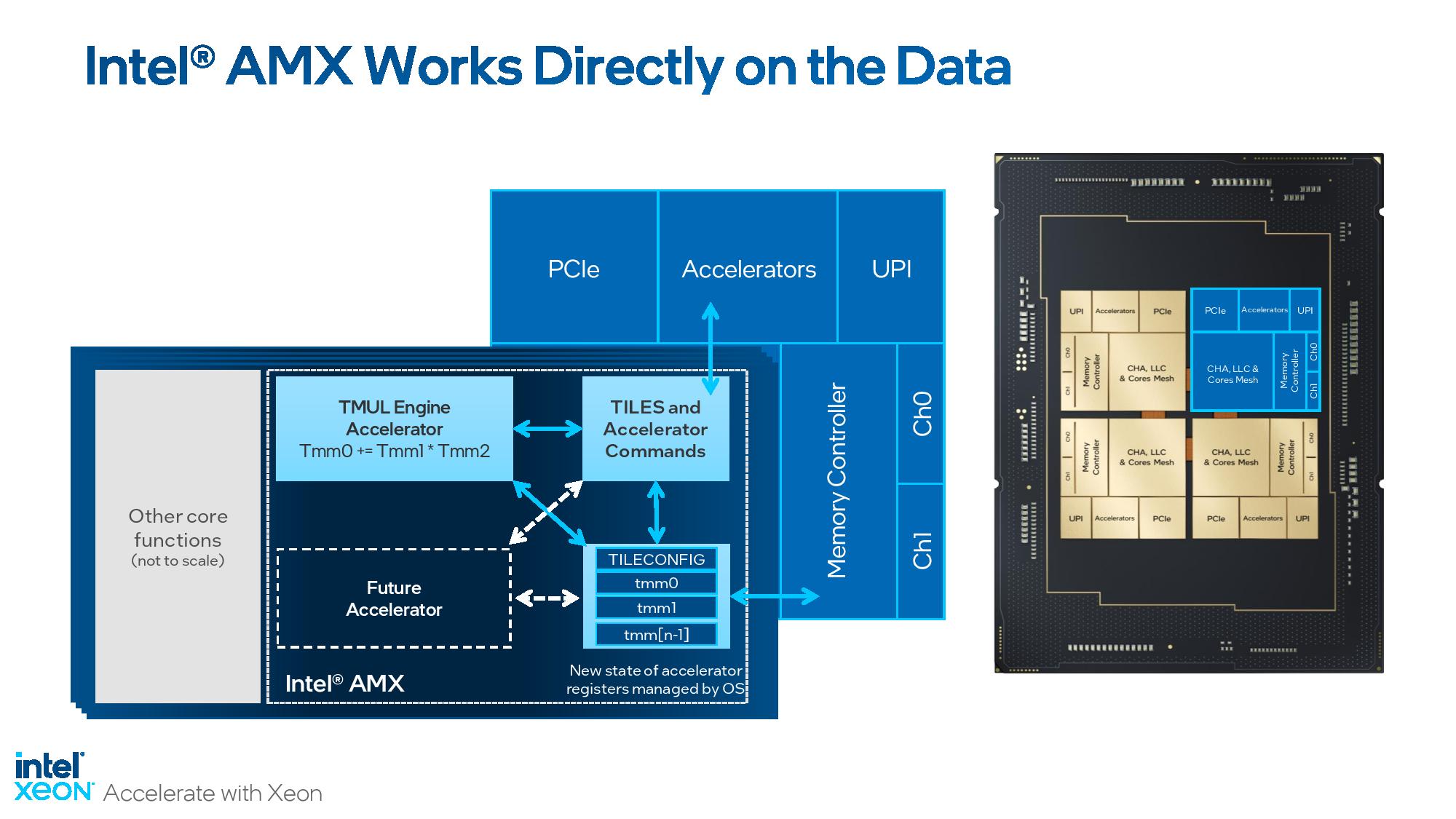
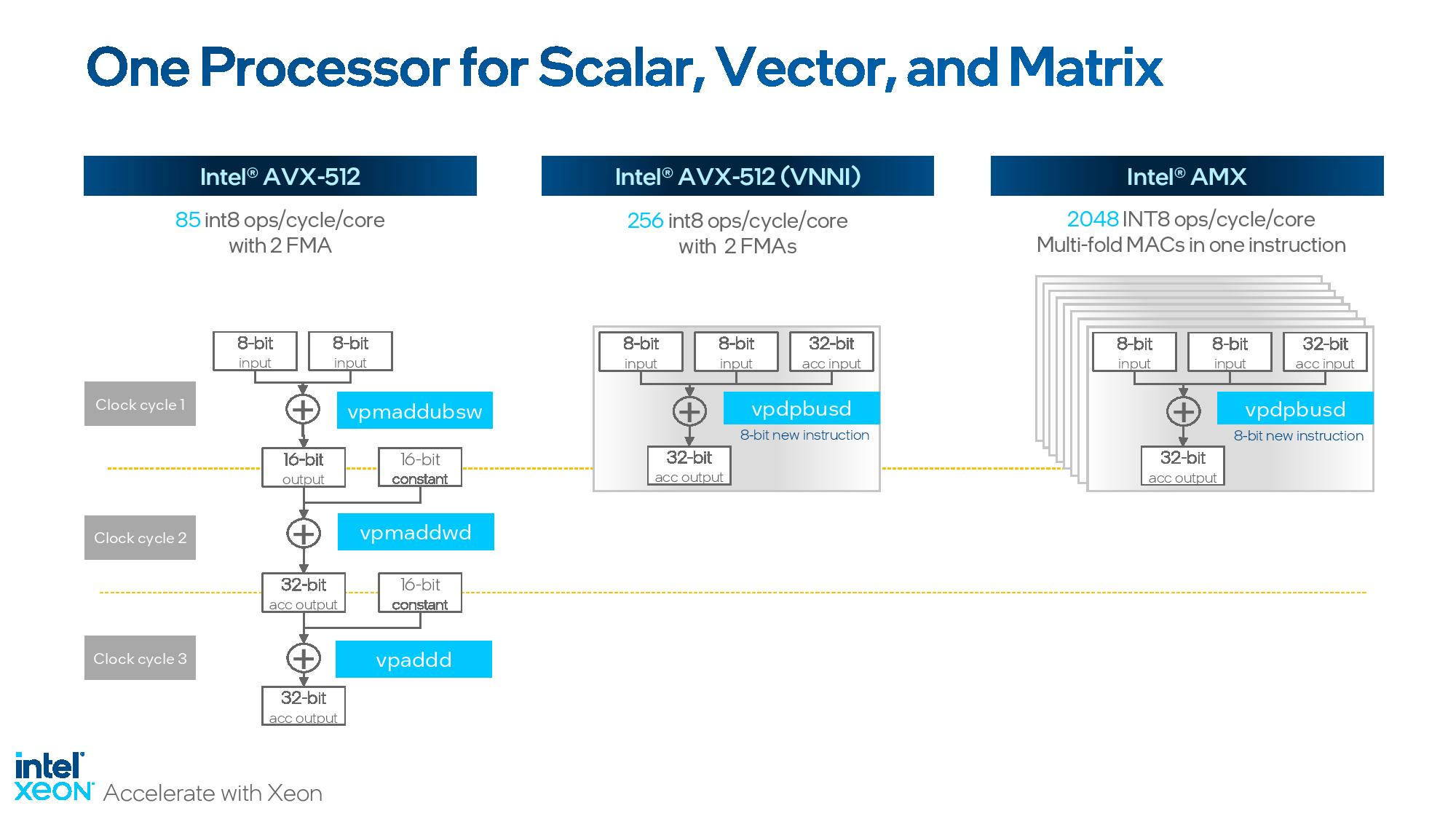

But a more important development lurks in the Sapphire Rapids silicon — Intel has now progressed to its new Advanced Matrix Extensions (AMX) x86 instructions, which deliver tremendous performance uplift in AI workloads by using a new set of two-dimensional registers called tiles. The Tile Matrix Multiply Unit (TMUL) that powers AMX is native to the Sapphire Rapids chips — you don't have to pay extra to use it like you do the dedicated AI accelerator engine — and leverages BF16 and INT8 to perform matrix multiply operations that can vastly enhance AI performance.
The benchmarks above leverage Intel's AMX, and not the optional in-built AI accelerator engine. Intel claims a 7X advantage over EPYC Genoa in ResNet34, a 34-layer object detection CNN model, using INT8 instructions at a batch size of 1 to measure latency — in this case, with an SLA of sub-100ms. Intel also claims a ~5.5X advantage in this same workload with a batched test. This model is trained in PyTorch but converted to the ONNX format.
Intel claims a ~3.3X advantage over AMD in ResNet50 (INT8 BS1) image classification with a sub-15ms SLA, and a 3X advantage in DLRM, a Deep Learning Recommendation Model, with PyTorch BF16 and INT8 in a batched workload.
We also see a ~5.5X advantage in BertLarge natural language processing with BF16, but that is versus Genoa with FP32, so it isn't an apples-to-apples test. Intel notes that BF16 datatypes were not supported with AMD's ZenDNN (Zen Deep Neural Network) library with TensorFlow at the time of testing, which leads to a data type mismatch in the BertLarge test. The remainder of the benchmarks used the same data types for both the Intel and AMD systems, but the test notes at the end of the above image album show some core-count-per-instance variations between the two tested configs -- we've followed up with Intel for more detail [EDIT: Intel responded that they swept across the various ratios to find the sweet spot of performance for both types of chips].
Overall, Intel claims that its AMX acceleration provides huge speedups in performance with industry-standard frameworks, but it's also important to call out the efficiency claims. The second yellow bar for each benchmark quantifies Intel's performance-per-watt claims, an incredibly important metric in today's power-constrained data centers — particularly with rising power costs in some climes, like the EU. Intel claims AMX delivers massive efficiency advantages when comparing two chips with similar core counts, which is surprising in light of Genoa's more advanced process node that tends to give it an efficiency advantage. Yes, dedicated silicon, as we see for AVX-512 and AMX, can be costly in terms of die area, and, thus, overall cost, but the advantages are huge if the applications can leverage the accelerators appropriately.
Intel's 32-core Xeon Platinum 8462Y+ chip squares off with AMD's 32-core EPYC Genoa 9354, but be aware that while these are iso-core-count comparisons, Intel lists the 8462Y+ for $5,945 while AMD lists the 9354 for $3,420, so the Intel chip costs 74% more. That said, the list pricing from both vendors is usually not reflective of what customers (particularly Tier 1 customers) actually pay, so take the pricing as a fuzzy guideline.
AMD does tend to offer higher core count chips at any given price point in the product stack and has a higher peak core count of 96 compared to Intel's 56 cores. Intel stuck with a 32-core vs 32-core comparison here, with per-core software licensing fees being the company's rationale for why these remain comparable. In fairness, software licensing, and other server BOM costs, like DDR5 memory and GPUs/accelerators, do have an outsized impact on solution-level pricing.
Given the size of Intel’s AI performance advantage with the 32-core parts, it’s reasonably safe to assume that it can compete with higher core count EPYC chips in these AI workloads, even if saddled with a reasonable amount of subpar workload/power scaling as they move to their own higher core count parts. Much of this performance can be chalked up to Intel's efforts on software enablement.
Intel doesn’t have any benchmark comparisons with LLMs (of the smaller variety), largely due to the raw and rapidly-changing nature of the LLM landscape. However, the company does say it is seeing impressive results with bandwidth-hungry LLMs on its HBM-equipped Xeon Max models (more below), which could be interesting given GPU shortages. We’re told that LLM benchmarks with Xeon Max will come in the future.
General Workloads: Intel Sapphire Rapids Xeon vs AMD EPYC Genoa
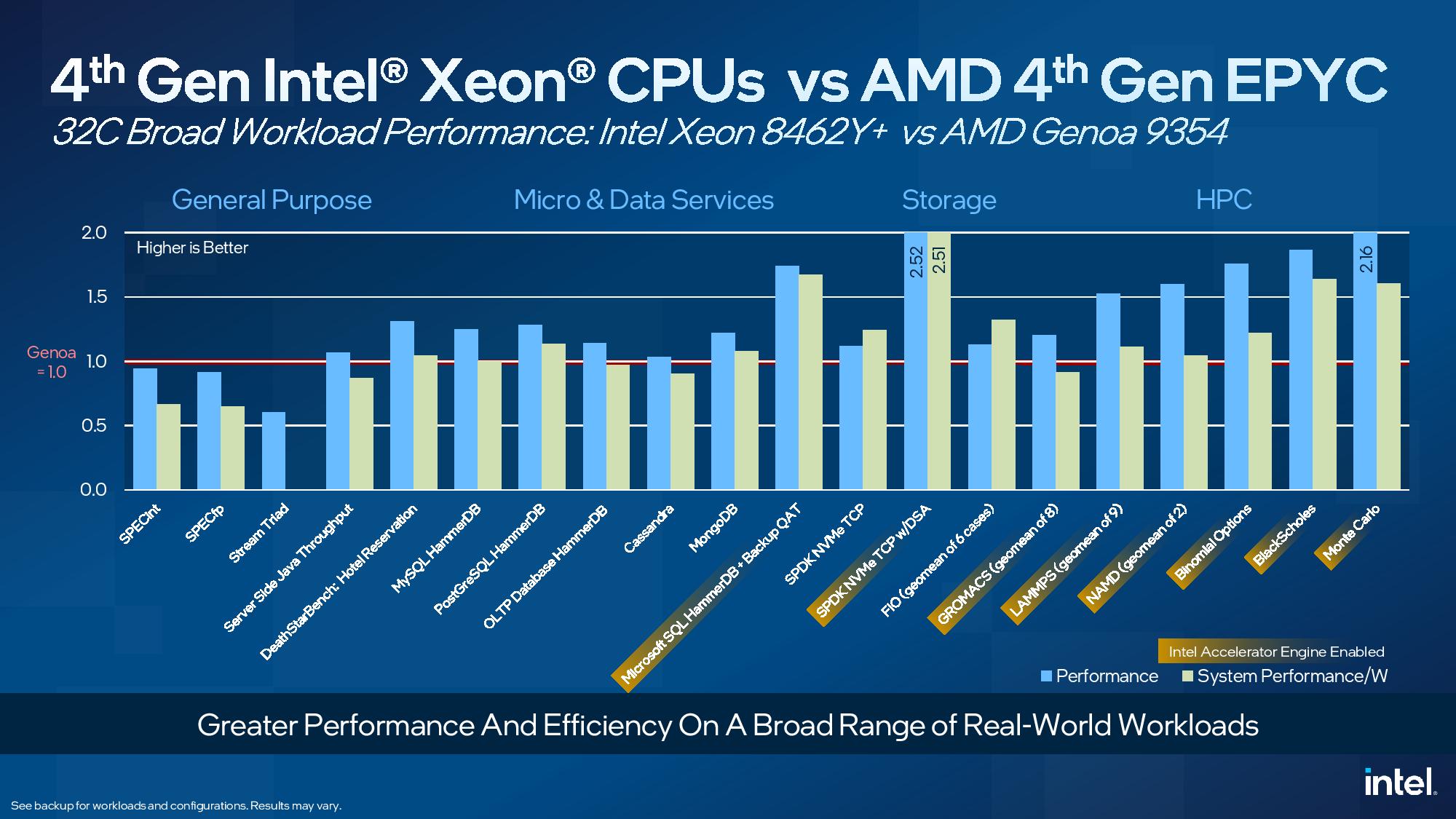
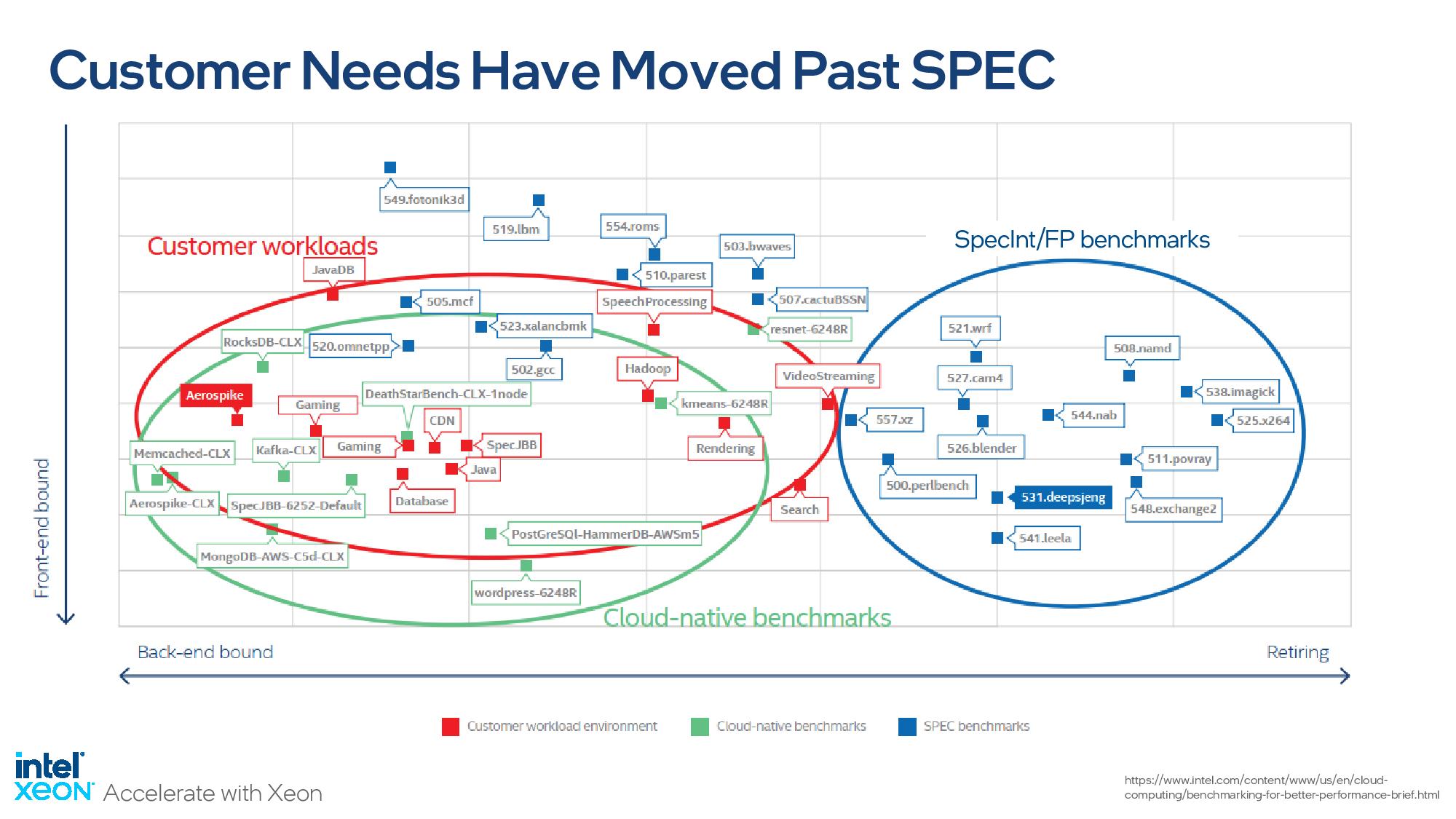






Here we see a standoff between the same two chips in a broader spate of general workloads. You'll note that Intel shows itself lagging Genoa in SPECint and SPECfp by large margins in efficiency and smaller margins in performance, but the company has recently begun de-emphasizing those industry-standard SPEC benchmarks because it feels the aging benchmark no longer represents real-world customer workloads -- that's actually not an uncommon viewpoint in the industry. Intel's take on SPEC is evidenced by the slideware they shared during the Sapphire Rapids briefings (second slide in above album). Intel says it is working on helping define the next generation of the venerable SPEC to make it more representative. For SPEC, Intel used the ICC compiler for Sapphire Rapids and AOCC for EPYC. The remainder of the benchmarks use 'mostly' the GCC compiler for both types of chips.
Intel also trails in the stream triad memory benchmark, which isn't surprising given that Sapphire Rapids has eight memory channels while Genoa has 12 (due to its higher channel count, AMD has 50% more memory capacity at its disposal in all of these benchmarks). That disparity also gives AMD an advantage in several other memory-bound workloads, like HPCG and Ansyst Fluent/Mechanical (not shown). It's clear that Intel is avoiding memory-bound workloads in these comparisons, though we do see those types of workloads in the HPC section where the company employs Xeon Max for comparison.
Intel largely claims slight performance gains in these workloads but notes that some of the larger gains come from employing its on-chip accelerator engines that require an extra fee to unlock. Intel used these engines in several of the workloads, marked in bronze on the horizontal axis, like SQL HammerDB, Gromacs, LAMMPs, NAMD, and others, to highlight the advantages of using the engines in tandem with applications that are tuned to exploit the advantages.
We haven't seen many benchmarks with these engines fully employed via software support, so it's clear that Intel is moving forward on the enablement front, and to good effect — at least according to its own benchmarks. Just be mindful that these accelerators, which speed AI, encryption/decryption, compression, data movement, and analytics, aren't available consistently across the Sapphire Rapids product stack and also cost extra.
There's also the matter of DPUs, too. These discrete accelerators can perform many of the same functions, such as encryption/decryption, compression, and data movement, at higher performance levels while also offloading the CPU, managing network traffic, and providing a separate control plane. Advanced DPU-augmented data center architectures aren't as widespread as the data center architectures that we consider 'traditional,' but that means the relative value of Intel's on-die accelerator engines will vary by deployment.
HPC Workloads : Intel Xeon Max vs AMD EPYC Genoa
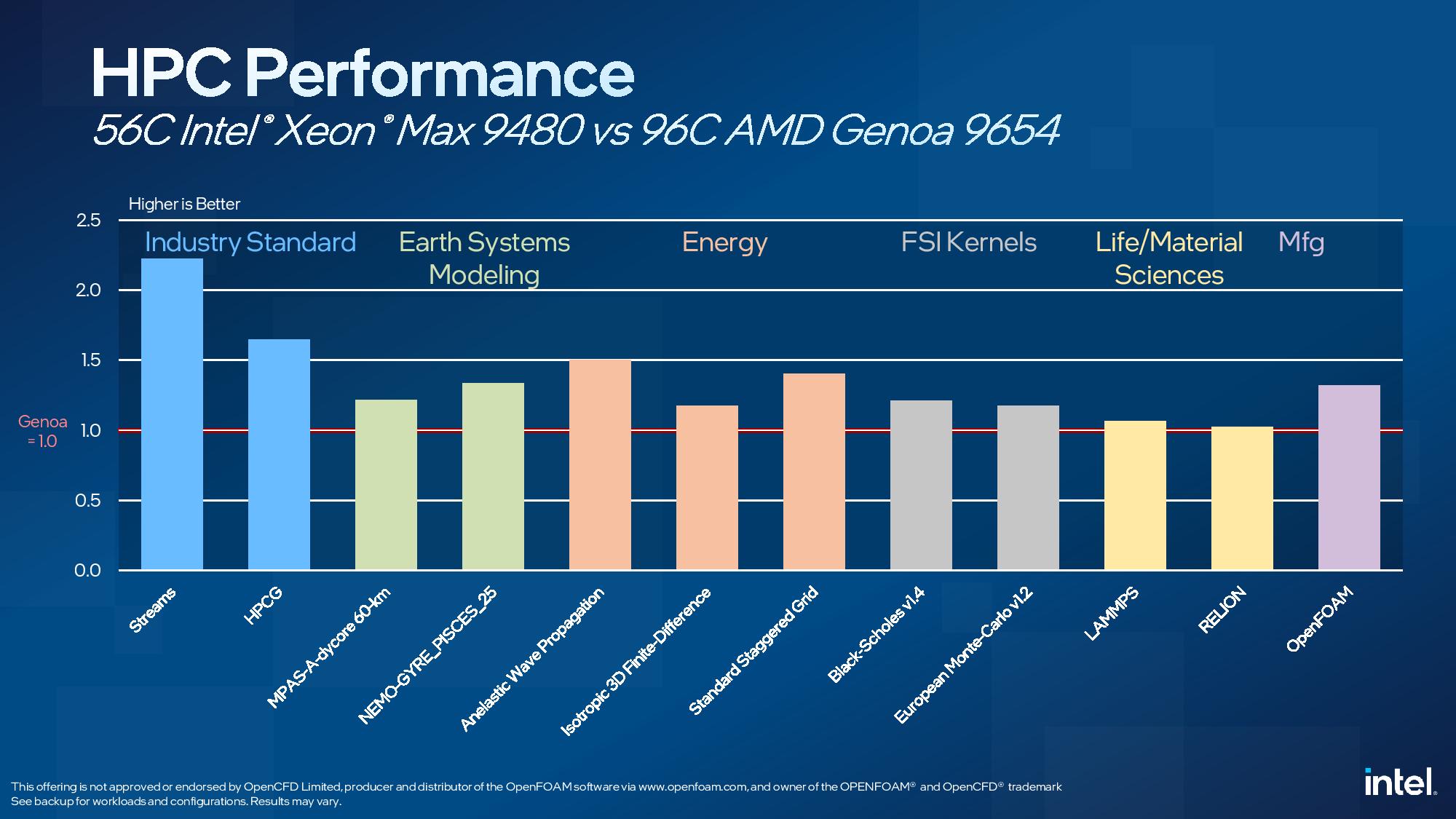



Here we see Intel's 56-core Xeon Max, the first x86 data center chip with on-package HBM to be pushed into full production, face off with AMD's 96-core EPYC Genoa flagship. Intel claims the onboard memory gives its smaller-but-not-less-expensive chip the advantage over the EPYC processor in a range of HPC-centric workloads, but without on-board accelerators enabled (oddly, only the data streaming accelerators are available on the Xeon Max models).
Naturally, these benchmarks won't land without plenty of dispute - there's a whole slew of architecture-specific optimizations possible for AMD's chips that could extract more performance, particularly in heavily-optimized HPC environments - but the key takeaway here is that Intel claims its HBM-equipped CPUs can offer compelling advantages in HPC that rival AMD's core-heavy flagships.
It is worth noting that both power scaling and chip fabrics can become a constraining factor with higher core-count chips in these types of workloads. As such, it's conceivable that some of these workloads could shift to a more favorable outcome for AMD with a slightly less prodigious model, like its own 64- or 56-core Genoa’s. Also, Intel's chips here only use the HBM2e memory -- there is no DDR5 attached. As such, AMD's Genoa has a tremendous memory capacity advantage (1.5TB of DDR5 capacity vs 128GB of HBM2e capacity for Xeon Max).
AMD has taken somewhat of a different path of augmenting its chips with extra memory by 3D-stacking the L3 cache for its Milan-X processors, and we expect the company to announce its newer Genoa-X chips tomorrow at its event tomorrow. However, AMD gears Milan-X for certain technical workloads, as opposed to positioning it for the broader HPC market as Intel does for Xeon Max.
TCO: Intel Sapphire Rapids Xeon vs AMD EPYC Genoa






Every vendor has its own take on how to calculate the Total Cost of Ownership (TCO), but they're all typically questionable -- overall TCO will vary so widely by deployment that it's truly hard to derive solid metrics that are indicative of broader trends.
Intel's take is that using the SPEC benchmark for deriving TCO values isn't indicative of real-world use cases, which we touched on briefly in the general workloads section above. As such, Intel provides a range of examples here for different types of deployments, and the associated savings of using Intel chips over AMD's EPYC. Some of these comparisons, like the QAT backup, aren't much better than using SPEC, so take them with a big grain of salt and be sure to check the configuration slides we've included in the album.
Intel also points to an accelerating pace of deployment, with 200 designs of 450+ Sapphire Rapids design wins already shipping. Intel also points out that it already has cloud instances in general availability at Google Cloud (notably paired with its Mount Evans IPU/DPU), and preview instances already available at several other cloud providers, like AWS. In contrast, AMD has yet to have any publicly available Genoa instances in the US, preview or otherwise, at cloud providers (we are aware of public instances available in China). We'll inquire about the status of AMD's cloud efforts at its event tomorrow and update as necessary.
Finally, Intel reiterates that its recently-revised data center roadmap remains on track, which you can read about here. We have a few questions still pending with Intel about the above benchmark test configurations, and will add more info as it becomes available.