“Sanskrit suits the language of computers and those learning artificial intelligence learn it,” Indian Space Research Organisation chairman S. Somanath said at an event in Ujjain on May 25. His was the latest in a line of statements exalting Sanskrit and its value for computing but without any evidence or explanation.
But beyond Sanskrit, how are other Indian languages faring in the realm of artificial intelligence (AI), at a time when its language-based applications have taken the world by storm?
The answer is a mixed bag. There is some passive discrimination even as the languages’ fates are buoyed by public-spirited research and innovation.
Inside ChatGPT
Behind both seemingly intelligent chatbots and art-making computers, algorithms and data-manipulation techniques turn linguistic and visual data into mathematical objects (like vectors), and combine them in specific ways to produce the desired output. This is how ChatGPT is able to respond to your questions.
When working with a language, a machine first has to break a sentence or a word down into little bits in a process called tokenisation. These are the bits that the machine’s data-processing model will work with. For example, “there’s a star” can be tokenised to “there”, “is”, “a”, and “star”.
There are several tokenisation techniques. A treebank tokeniser breaks up words and sentences based on the rules that linguists use to study them. A subword tokeniser allows the model to learn some common word and modifications to that word separately, such as “dusty” and “dustier”/“dustiest”.
OpenAI, the maker of ChatGPT and the GPT series of large language models, uses a type of the subword tokeniser called byte-pair encoding (BPE). Here’s an example of the OpenAI API using this on a statement by Gayathri Chakravorty Spivak:
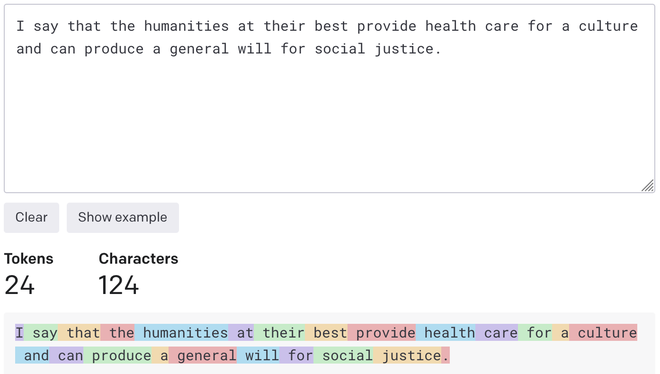
English v. Hindi
In 2022, Amazon released a parallel database of 1 million utterances in 52 languages, called MASSIVE. ‘Parallel’ means the same utterance is presented in multiple languages. An utterance can be a simple query or phrase. For example, no. 38 in the Tamil section is “என்னுடைய திரையின் பிரகாசம் குறைவாக இயங்குகிறதா?” – meaning “does my screen’s brightness seem low?”.
On May 3 this year, AI researcher Yennie Jun combined the OpenAI API and MASSIVE to analyse how BPE would tokenise 2,033 phrases in the 52 languages.
Ms. Jun found that Hindi phrases were tokenised on average into 4.8x more tokens than their corresponding English phrases. Similarly, the tokens for Urdu phrases were 4.4x longer and for Bengali, 5.8x longer. Running a model with more tokens increases its operational cost and resource consumption.
Both GPT and ChatGPT can also admit a fixed number of input tokens at a time, which means their ability to parse English text is better than to parse Hindi, Bengali, Tamil, etc. Ms. Jun wrote that this matters because ChatGPT has been widely adopted “in various applications (from language learning platforms like Duolingo to social media apps like Snapchat),” spotlighting “the importance of understanding tokenisation nuances to ensure equitable language processing across diverse linguistic communities.”
ChatGPT can switch
Generally, AI expert Viraj Kulkarni said, it is “fairly difficult” for a model trained to work with English to be adapted to work with a language with different grammar, like Hindi.
“If you take [an English-based] model and fine-tune it using a Hindi corpus, the model might be able to reuse some of its understanding of English grammar, but it will still need to learn representations of individual Hindi words and the relationships between them,” Dr. Kulkarni, chief data scientist at Pune-based DeepTek AI, said.
Sentences in different languages are thus tokenised in different ways, even if they have the same meaning. Here’s Dr. Spivak’s statement in German, thanks to Google Translate:
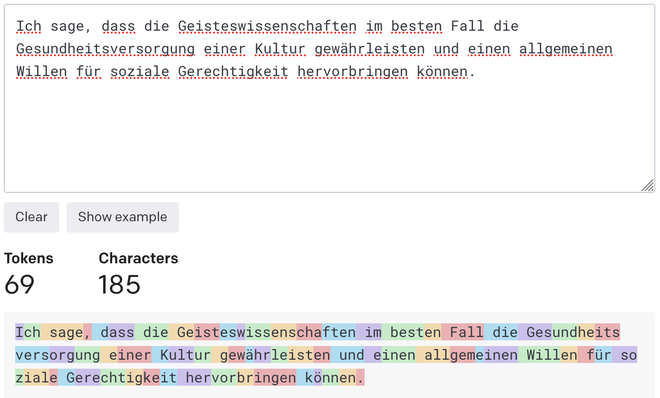
This said, ChatGPT in particular doesn’t struggle with other languages. According to Dr. Kulkarni, GPT-4, which powers the premium version of ChatGPT, was trained in English as well as “pretty much most major languages in the world, [so it] has no preference towards English or any other language.”
“It may be better at English than Hindi because it may have seen more English texts than Hindi texts, but it can very fluidly switch between languages,” he added.
But there is still a cost difference. In January 2023, machine-learning expert Denys Linkov fed the first 50 utterances in English in MASSIVE to ChatGPT along with a prompt: “Rewrite the following sentence into a friendlier tone”. He repeated the task with the first 50 Malayalam utterances. He found that the latter used 15.69-times more tokens.
OpenAI charges a fixed rate to use ChatGPT based on the number of tokens, so Malayalam was also 15.69-times more expensive.
More and more data
This said, for models designed to work with individual languages, adapting could be a problem – as could any language that doesn’t have much indexed material available for the model to train with. This is true of many Indian languages.
“Recent breakthroughs indicate quite unequivocally that the biggest gains in [model] performance come from only two factors: the size of the network, or number of parameters, and the size of the training data,” per Dr. Kulkarni.
A parameter is a way in which words can be different from each other. For example, word type (verbs, adjectives, nouns, etc.) can be one parameter and tense can be another. GPT-4 has trillions of parameters. The more parameters a model has, the better its abilities.
The amount of training data for English is much larger than that for Indian languages. ChatGPT was trained on text scraped from the internet – a place where some 55% of the content is in English. The rest is all the other languages of the world combined. Can it suffice?
We don’t know. According to Dr. Kulkarni, there is no known “minimum size” for a training dataset. “The minimum size also depends on the size of the network,” he explained. “A large network is more powerful, can represent more complex functions, and needs more data to reach its maximum performance.”
Data for ‘fine-tuning’
“The availability of text in each language is going to be a long-tail – a few languages with lots of text, many languages with few examples” – and this is going to affect models dealing with the latter, Makarand Tapaswi, a senior machine learning scientist at Wadhwani AI, a non-profit, and assistant professor at the computer vision group at IIIT Hyderabad, said.
“For rare languages,” he added, the model could be translating the words first to English, figuring out the answer, then translating back to the original language, “which can also be a source of errors”.
“In addition to next-word prediction tasks, GPT-like models still need some customisation to make sure they can follow natural language instructions, carry out conversations, align with human values, etc.,” Anoop Kunchukuttan, a researcher at Microsoft, said. “Data for this customisation, called ‘fine-tuning’, needs to be of high quality and is still available mostly in English only. Some of this exists for Indian languages, [while] data for most kinds of complex tasks needs to be created.”
Amazon’s MASSIVE is a step in this direction. Others include Google’s ‘Dakshina’ dataset with scripts for a dozen South Asian languages; and the open-source ‘No Language Left Behind’ programme, to create “datasets and models” that narrow “the performance gap between low- and high-resource languages”.
Meet AI4Bharat
In India, AI4Bharat is an IIT Madras initiative that is “building open-source language AI for Indian languages, including datasets, models, and applications,” according to its website.
Dr. Kunchukuttan is a founding-member and co-lead of the Nilekani Centre at AI4Bharat. To train language models, he said, AI4Bharat has a corpus called IndicCorp with 22 Indian languages, and its CommonCrawl website-crawler can support “10-15 Indian languages”.
One part of natural language processing is natural language understanding (NLU) – in which a model works with the meaning of a sentence. For example, when asked “what’s the temperature in Chennai?”, an NLU model might perform three tasks: identify that this is a weather-related (1) question in need of an answer (2) pertaining to a city (3).
In a December 2022 preprint paper (updated on May 24, 2023), AI4Bharat researchers reported a new benchmark for Indian languages called “IndicXTREME”. They wrote that IndicXTREME has nine NLU tasks for 20 languages in the Eighth Schedule of the Constitution, including nine for which there aren’t enough resources with which to train language models. It allows researchers to evaluate the performance of models that have ‘learnt’ these languages.
Modest-sized models
Preparing such tools is laborious. For example, on May 25, AI4Bharat publicly released ‘Bharat Parallel Corpus Collection’, “the largest publicly available parallel corpora for Indic languages”. It contains 23 crore text-pairs; of these, 6.44 lakh were “manually translated”.
These tools also need to account for dialects, stereotypes, slang, and contextual references based on caste, religion, and region.
Computational techniques can help ease development. In a May 9 preprint paper, an AI4Bharat group addressed “the task of machine translation from an extremely low-resource language to English using cross-lingual transfer from a closely related high-resource language.”
“I think we are at a point where we have data to train modest-sized models for Indian languages, and start experimenting with the directions … mentioned above,” Dr. Kunchukuttan said. “There has been a spurt in activity of open-source modest-sized models in English, and it indicates that we could build promising models for Indian languages, which becomes a springboard for further innovation.”







