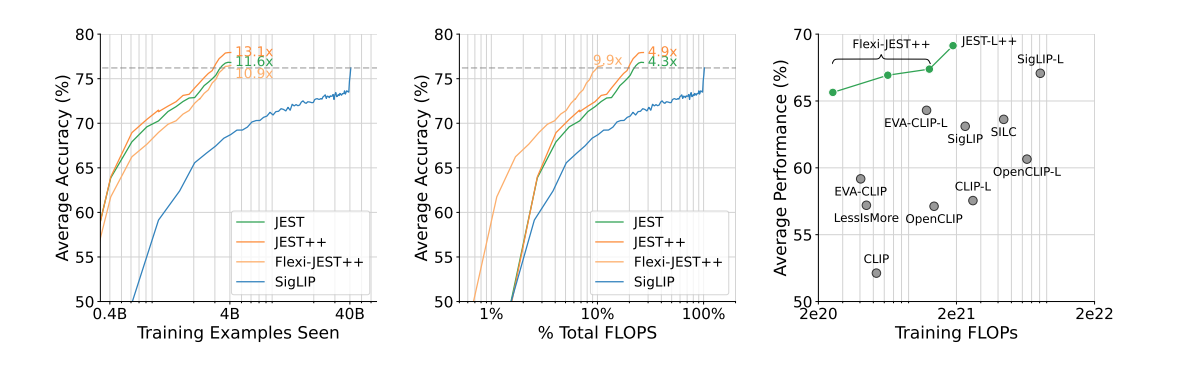
Google DeepMind, Google's AI research lab, has published new research on training AI models that claims to greatly accelerate both training speed and energy efficiency by an order of magnitude, yielding 13 times more performance and ten times higher power efficiency than other methods. The new JEST training method comes in a timely fashion as conversations about the environmental impact of AI data centers are heating up.
DeepMind's method, dubbed JEST or joint example selection, breaks apart from traditional AI model training techniques in a simple fashion. Typical training methods focus on individual data points for training and learning, while JEST trains based on entire batches. The JEST method first creates a smaller AI model that will grade data quality from extremely high-quality sources, ranking the batches by quality. Then it compares that grading to a larger, lower-quality set. The small JEST model determines the batches most fit for training, and a large model is then trained from the findings of the smaller model.
The paper itself, available here, provides a more thorough explanation of the processes used in the study and the future of the research.
DeepMind researchers make it clear in their paper that this "ability to steer the data selection process towards the distribution of smaller, well-curated datasets" is essential to the success of the JEST method. Success is the correct word for this research; DeepMind claims that "our approach surpasses state-of-the-art models with up to 13× fewer iterations and 10× less computation."
Of course, this system relies entirely on the quality of its training data, as the bootstrapping technique falls apart without a human-curated data set of the highest possible quality. Nowhere is the mantra "garbage in, garbage out" truer than this method, which attempts to "skip ahead" in its training process. This makes the JEST method much more difficult for hobbyists or amateur AI developers to match than most others, as expert-level research skills are likely required to curate the initial highest-grade training data.
The JEST research comes not a moment too soon, as the tech industry and world governments are beginning discussions on artificial intelligence's extreme power demands. AI workloads took up about 4.3 GW in 2023, almost matching the annual power consumption of the nation of Cyprus. And things are definitely not slowing down: a single ChatGPT request costs 10x more than a Google search in power, and Arm's CEO estimates that AI will take up a quarter of the United States' power grid by 2030.
If and how JEST methods are adopted by major players in the AI space remains to be seen. GPT-4o reportedly cost $100 million to train, and future larger models may soon hit the billion-dollar mark, so firms are likely hunting for ways to save their wallets in this department. Hopefuls think that JEST methods will be used to keep current training productivity rates at much lower power draws, easing the costs of AI and helping the planet. However, much more likely is that the machine of capital will keep the pedal to the metal, using JEST methods to keep power draw at maximum for hyper-fast training output. Cost savings versus output scale, who will win?



.png?w=600)