At the recent Hot Chips 2024 symposium in Stanford, California, Enfabrica introduced its Accelerated Compute Fabric SuperNIC (ACF-S) silicon and system-level solutions.
Designed to scale AI networks to millions of GPUs, it offers higher bandwidth, greater resiliency, lower latency, and enhanced programmatic control for data center operators.
The presentation, titled “ACF-S: An 8 Terabit/sec SuperNIC for High-Performance Data Movement in AI and Accelerated Compute Networks,” featured Enfabrica’s Chief Development Officer and Co-Founder, Shrijeet Mukherjee, alongside technical engineer Thomas Norrie. They discussed the architecture, design, and technical attributes of their first-generation ACF SuperNIC silicon, codenamed “Millennium.”
Built differently
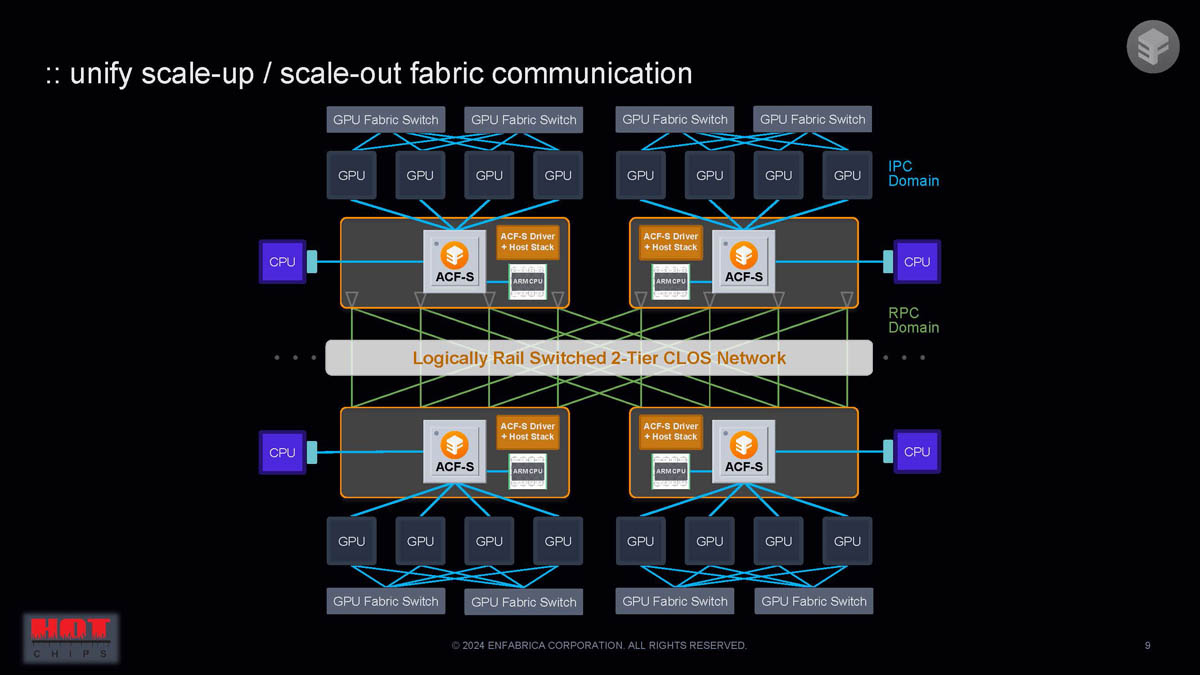
Covering the event, ServeTheHome noted Enfabrica’s ACF-S aims to unify scale-up (adding resources to a single system) and scale-out (connecting multiple systems) fabric communication.
Although the network layout may resemble traditional PCIe switch-based networks, it is not a PCIe switch. Instead, it employs a logically rail-switched 2-tier CLOS network architecture that connects multiple CPUs, GPUs, and other components via ACF-S chips and GPU fabric switches. This architecture supports flexible, high-performance communication across different computing domains (like IPC and RPC), enabling efficient handling of data-intensive tasks without the constraints of conventional PCIe switch designs.
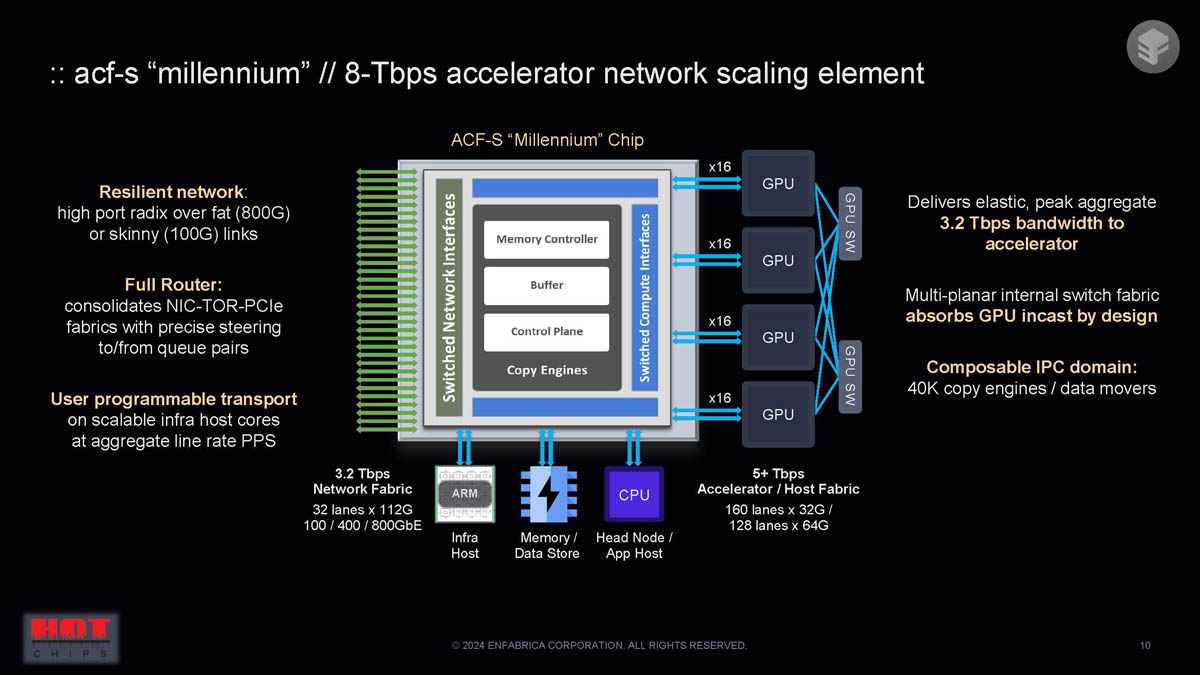
The ACF-S "Millennium" chip is a key component, designed to deliver resilient networking for GPUs with 3.2 Tbps bandwidth per accelerator. It features a full router, multi-planar internal switch fabric, and user-programmable transport, supporting scalable infrastructure with up to 40,000 copy engines and data movers.
Enfabrica notes that the Millennium chip is built differently by integrating higher chip I/O density, NICs within crossbars, scalable memory translation, and shared flow buffer and packet processing, all of which enhance performance and efficiency.
Enfabrica’s approach essentially focuses on maximizing compute efficiency by optimizing hardware and software integration, enhancing I/O and memory scalability, and implementing smart traffic management to improve network performance and system resilience. As ServeTheHome summarizes, “It is like taking a bunch of NICs and combining them, and PCIe switches, and combining all of these into one. The other interesting use case is that one could add CXL memory to the ACF-S fabric and present pools of CXL memory without hosts. This is super cool.”








