
The vast majority of leading supercomputers and AI clusters today use CPUs for general-purpose tasks and orchestration and AI GPUs for massive parallel computing workloads to achieve exceptionally high ExaFLOPS-class performance. But in China, we are seeing a different trend, as in recent years the country has deployed a number of CPU-only supercomputers for AI and HPC workloads, largely due to the bans on GPUs from the US preventing the country from sourcing enough for supercomputers. For example, China's National Supercomputing Center recently deployed its 1.54 ExaFLOPS-class machine that uses 20,480 Armv9-based CPUs.
The LineShine LX2 processor
The LineShine supercomputer is based around custom Armv9-based LX2 processors designed specifically for large-scale AI and HPC workloads. China's National Supercomputing Center (NSCC) in Shenzhen does not disclose the developer of the LX2 CPU, though Jon Peddie from Jon Peddie Research outright calls it the 'Huawei LX2' processor. Meanwhile, the CPU could be a custom Huawei HPC CPU, a joint NSCC/Huawei design, or an entirely separate Chinese government-backed HPC processor developer.
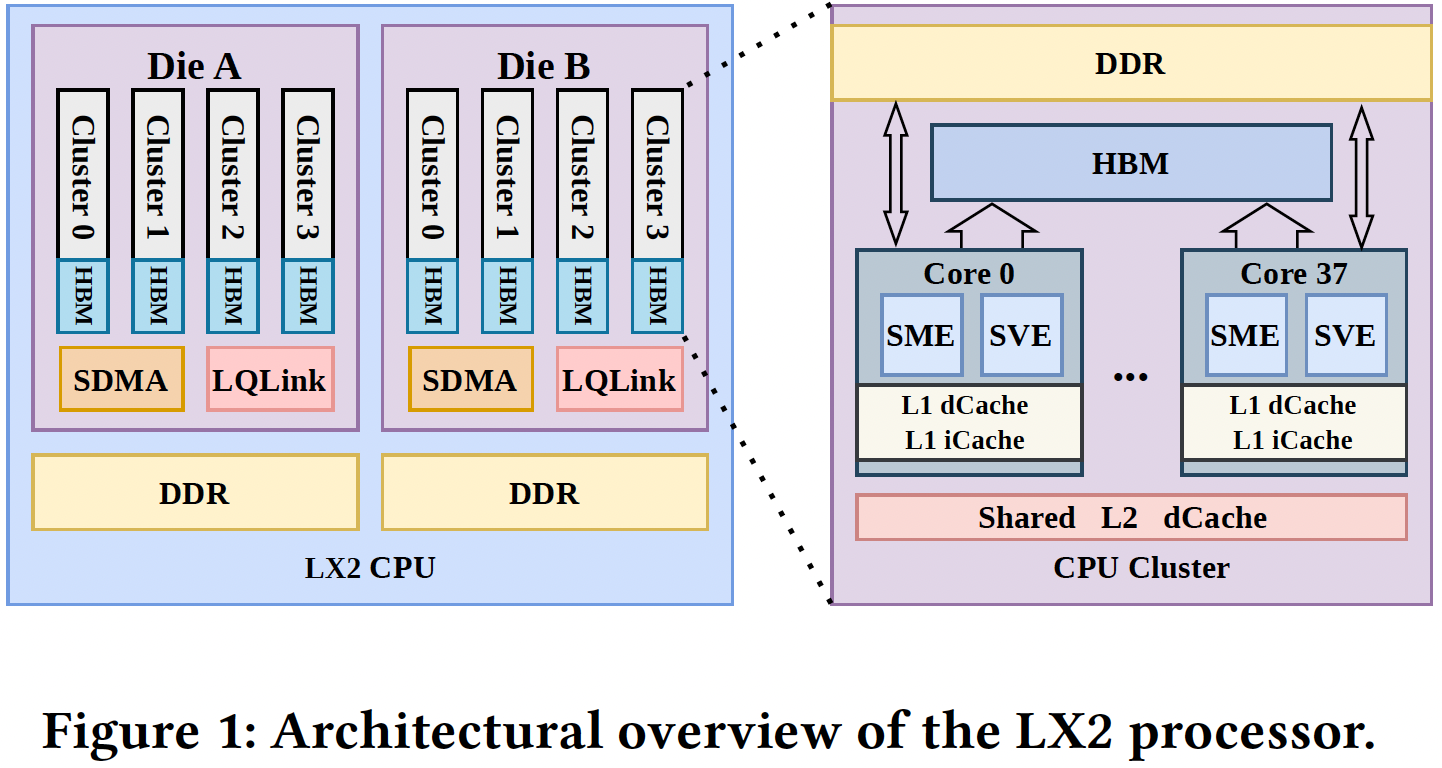
Each LX2 processor uses two compute chiplets and has a total of 304 CPU cores organized into eight CPU clusters containing 38 cores each. Every core includes Arm SVE (Scalable Vector Extension) and SME (Scalable Matrix Extension) units that accelerate vector and matrix operations used in AI training and scientific computing that support FP64, FP32, BF16, FP16, and INT8 data formats. Each core is equipped with 32 KB L1 instruction cache and 32 KB L1 data cache, while every cluster shares a 28.5 MB L2 cache.
Go deeper with TH Premium: AI and data centers

- Photonics and high-speed data movement is the next big AI bottleneck
- The data center cooling state of play
- Massive AI data center buildouts are squeezing energy supplies
- Ultra Ethernet: The data center interconnection of tomorrow
The processor uses a highly unusual memory subsystem that combines 32 GB of on-package HBM that delivers up to 4 TB/s of bandwidth and up to 256 GB of off-package DDR5 memory. A similar memory subsystem was used by Fujitsu's Arm-based A64FX processor that powers the Fugaku supercomputer, though the LX2 is probably the industry's first Armv9-based CPU for AI and HPC that uses such a memory subsystem.
Each chiplet contains four HBM domains and four DDR domains; there are 16 NUMA domains per processor. HBM access is highly sensitive to locality, whereas DDR memory access is more uniform within a die and is shared between clusters. Such behavior forced developers to design topology-aware memory placement and scheduling techniques (which are particularly handy for AI training), which are executed by a dedicated SDMA engine to move data between DDR and HBM.
When it comes to performance, a single LX2 processor delivers 60.3 TFLOPS FP64 performance, 240 TFLOPS BF16/FP16 throughput, and 960 TOPS INT8 performance. Unlike conventional server CPUs, the architecture appears heavily optimized for dense AI and matrix workloads despite remaining a CPU-centric design. The paper notes that sustaining high utilization of the SME matrix engines required extensive co-design of kernels, runtime scheduling, cache residency management, and tensor placement across the HBM and DDR hierarchy.
The LineShine supercomputer
The LineShine supercomputer comprises 20,480 compute nodes, each node contains two LX2 processors, and each LX2 processor has 304 CPU cores. Therefore, the whole system uses 40,960 LX2 processors packing 2,451,840 CPU cores in total. The supercomputer is interconnected by the LingQi high-speed network (LQLink) with 1.6 Tb/s per node.
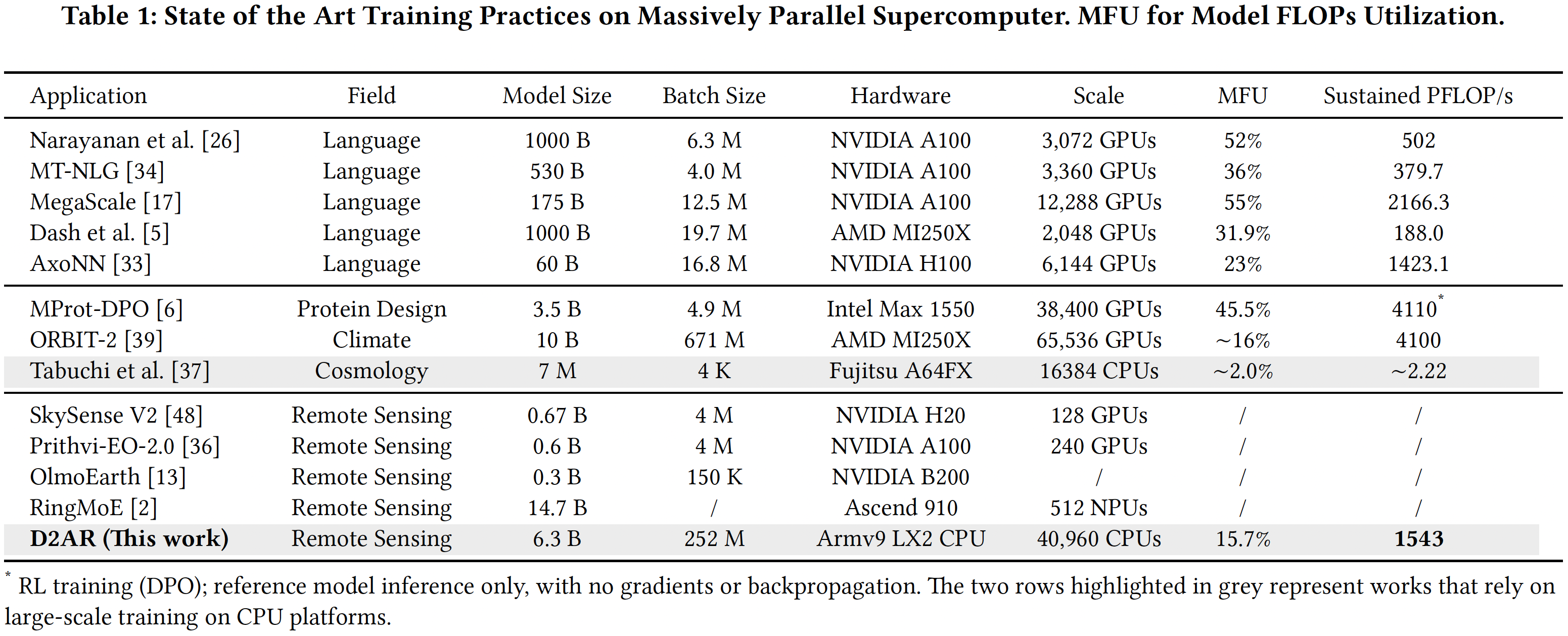
The machine delivers 1.54 ExaFLOP/s of BF16 training performance and peaks at 2.16 ExaFLOP/s during training of a 6.3-billion-parameter Earth observation generative compression model. Since companies like xAI do not publish peak performance of their AI clusters that use hundreds of thousands of AI GPUs from Nvidia, we cannot compare the performance of LineShine to that of Colossus or other advanced AI clusters. Yet, theoretical peak performance of xAI's Colossus is believed to be 497.9 ExaFLOPS, so even with a model FLOPS utilization of around 15% (like the LineShine does), it can deliver around 75 ExaFLOPS.
When it comes to theoretical peak FP64 performance, these 40,960 LX2 processors can deliver 2.47 ExaFLOPS, though we have no idea about the actual FP64 throughput of the machine, as it heavily depends on multiple factors.
Loads of advantages, but with a caveat
CPU-only AI and HPC supercomputers offer several advantages over conventional heterogeneous CPU+GPU systems, specifically for complex scientific tasks that combine AI training with massive data ingestion, preprocessing, storage interaction, simulation, and orchestration.
Since everything runs on the same processor and memory space, they avoid many of the complications associated with heterogeneous computing, such as costly and bandwidth-hungry CPU-to-GPU data transfers, complex programming models, GPU memory limitations, and accelerator-specific software stacks.
Furthermore, homogeneous CPU-based systems can expose much larger coherent memory pools by combining HBM with large DDR capacities, which is useful for handling massive scientific datasets, retrieval-augmented generation, and long-context windows.
In addition, they are attractive for AI-for-science applications that involve irregular control flow, distributed I/O, communication-heavy pipelines, and execution patterns that do not map efficiently to GPUs.
Also, CPU-only systems can integrate more naturally with traditional HPC environments and perform regular supercomputer tasks (e.g., simulations), which is particularly useful for those who need both AI training/inference and HPC.
Last but not least, such systems reduce dependence on foreign accelerators and platforms like Nvidia's GPUs and the CUDA software ecosystems, which is important for China.
There is a big tradeoff, though: CPU-only systems are usually less power-efficient and deliver lower dense AI throughput than GPU-based supercomputers, which is why the industry bets on heterogeneous CPU+GPU architectures.







