
Neither AMD nor Nvidia intends to back out of this argument involving the performance difference between the Instinct MI300X and the H100 (Hopper) GPUs. But AMD does make some strong points while comparing FP16 using vLLM, which is a more popular choice against FP8, which works only with TensorRT-LLM.
The red team announced the MI300X graphics accelerator early this December, claiming up to 1.6X lead over Nvidia's H100. Two days ago, Nvidia fired back by saying AMD did not use its optimizations when comparing the H100 with TensorRT-LLM. The reply reached a single H100 against eight-way H100 GPUs while running the Llama 2 70B chat model.
The Continued War of Benchmark Results and Test Scenarios
In this latest response, AMD said that Nvidia used a selective set of inferencing workloads. It further identified that Nvidia benchmarked these using its in-house TensorRT-LLM on H100 rather than vLLM, an open-source and widely used method. Furthermore, Nvidia used the vLLM FP16 performance datatype on AMD while comparing its results with DGX-H100, which used the TensorRT-LLM with FP8 datatype to display these alleged misconstrued results. AMD stressed that in its test, it used vLLM with the FP16 dataset due to its widespread use, and vLLM does not support FP8.
There's also the point that servers will have latency, but instead of accounting for that, Nvidia showed its throughput performance, not emulating the real-world situation, according to AMD.
AMD's Updated Test Results with More Optimizations and Accounting for Latency with Nvidia's Testing Method
AMD made three performance runs using Nvidia's TensorRT-LLM, the last notable one having measured latency results between MI300X and vLLM using the FP16 dataset against H100 with TensorRT-LLM. But the first test involved a comparison between the two using vLLM on both, hence FP16, and for the second test, it compared its MI300X's performance with vLLM while comparing TensorRT-LLM.
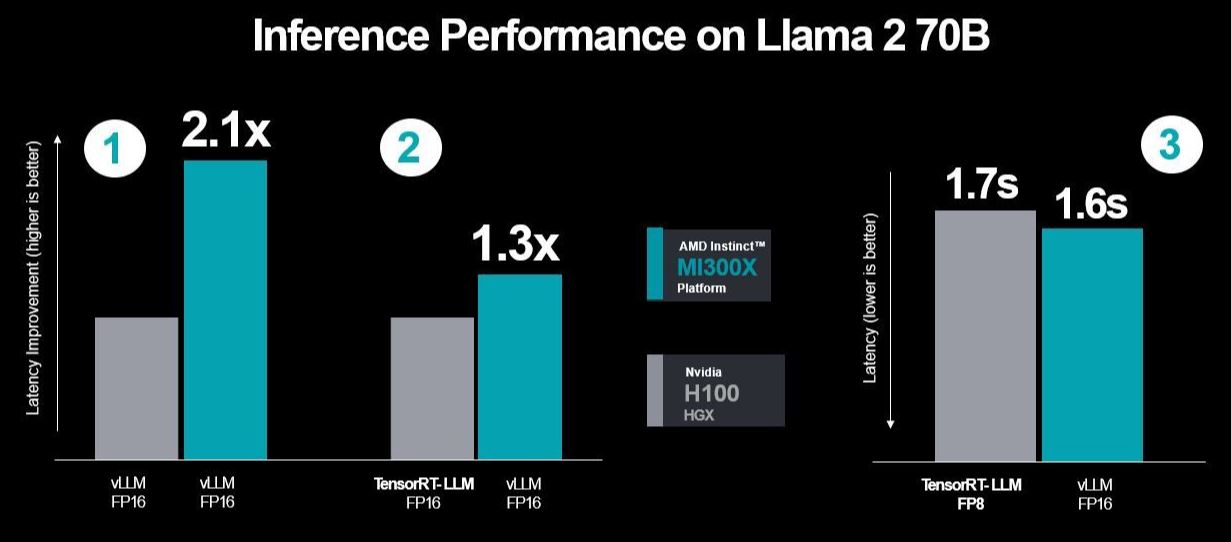
So, AMD used the same selected testing scenario Nvidia did with its second and third test scenarios, showing higher performance and reduced latency. The company added more optimizations when compared to H100 while running vLLM on both, offering a 2.1x boost in performance.
It is now up to Nvidia to evaluate how it wants to respond. But it also needs to acknowledge that this would require the industry to ditch FP16 with TensorRT-LLM's closed system for using FP8, essentially ditching vLLM for good. While referring to Nvidia's premium, a Redditor once said, "TensorRT-LLM is free just like the things that come free with a Rolls Royce."







