
OpenAI has created a new model called CriticGPT that has been designed to spot errors in programming code produced by GPT-4.
In a blog post, OpenAI announced that it trained the new bug-catching model on GPT-4 and found that when people use CriticGPT to review code that ChatGPT itself had written, they outperformed those without AI help 60% of the time.
While you should always double-check anything made by AI, this is a step towards improved output quality. OpenAI says users can now be more confident in the code produced by the chatbot.
That being said, OpenAI added the disclaimer that “CriticGPT’s suggestions are not always correct”.
Increasingly harder to find super smart AI's mistakes
We’ve trained a model, CriticGPT, to catch bugs in GPT-4’s code. We’re starting to integrate such models into our RLHF alignment pipeline to help humans supervise AI on difficult tasks: https://t.co/5oQYfrpVBuJune 27, 2024
There are at least two main ways in which this new model from OpenAI is good news for ChatGPT’s users. The more obvious way is that since we know the outputs AI chatbots produce should still be supervised by a pair of human eyes, the burden of this supervisory task can be somewhat lightened by the added AI assistance that’s been specifically trained to spot mistakes.
Secondly, OpenAI said it will start to integrate models similar to CriticGPT into its “Reinforcement Learning from Human Feedback” (RLHF) alignment pipeline to help humans supervise AI on difficult tasks.
OpenAI said that a key part of this process entails people it calls AI trainers rating different ChatGPT responses against each other. This process works relatively fine for now but as ChatGPT becomes more accurate and its mistakes more subtle, the task for AI trainers to spot inaccuracies may become increasingly difficult.
“This is a fundamental limitation of RLHF, and it may make it increasingly difficult to align models as they gradually become more knowledgeable than any person that could provide feedback,” OpenAI said.
Last year, OpenAI already explained that future generations of AI systems could become too complex for humans to fully understand. If a model generates a million lines of complex code, would you trust a human to be able to reliably determine whether the code is safe to run or not?
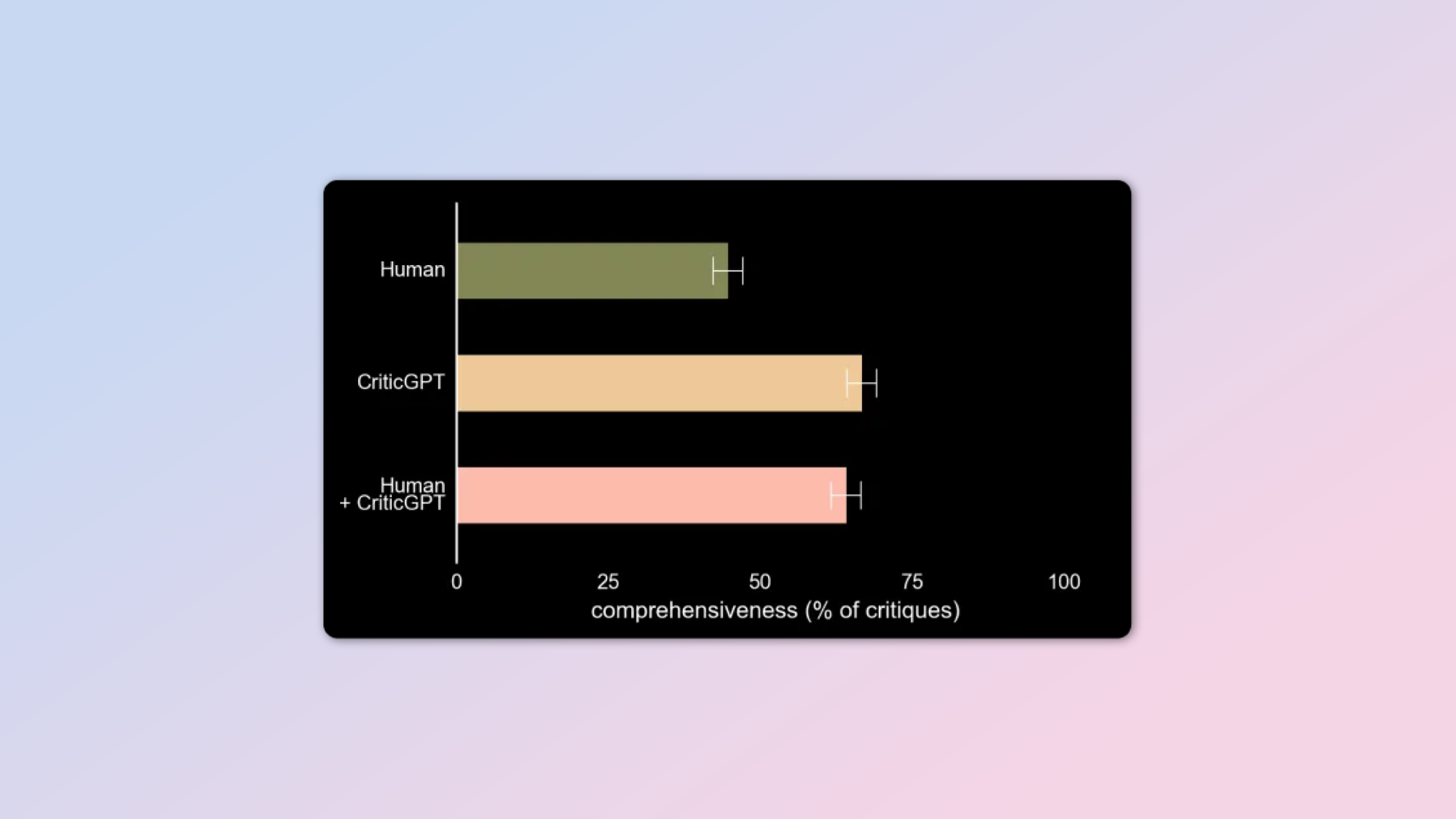
CriticGPT’s training involved pouring over inputs that contained mistakes which it then had to critique. AI trainers manually inserted mistakes into code written by ChatGPT and wrote sample feedback as if they had caught the mistake themselves to help train the model. Experiments were then done to check whether CriticGPT could catch both manually inserted bugs and ones that ChatGPT happened to insert on its own.
AI trainers ended up liking CriticGTPs's feedback over that given by ChatGPT in 63% of the cases where the bugs were naturally occurring, partly because the new model was less nit-picky and didn’t bring up small complaints that were unhelpful from a practical sense. It also hallucinated problems less often.







